- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
ImageCLEF 2008: Visual Concept Detection Task
In 2008, ImageCLEF will offer a Visual Concept Detection Task continuing the Object Annotation Task of ImageCLEF 2006 and the Object Retrieval Task of ImageCLEF 2007. In contrast to its predecessors, the Visual Concept Detection Task of ImageCLEF 2008 will be strongly interacting with the ImageCLEF 2008 Photographic Retrieval Task.
Outline
The Visual Concept Detection Task has the objective to identify visual concepts that would help in solving the photographic retrieval task in ImageCLEF 2008.
Therefore we will publish a training database of approximately 1,800 images which are classified according to the concept hierarchy described in the following section along with their classification. Only these data may be used to train concept detection/annotation techniques.
At a later stage, we will publish a test database of 1,000 images. For each of these images participating groups are required to determine the presence/absence of the concepts.
At a later stage, the usefullness of the detected topics for the retrieval procedure will be evaluated. Groups who are interested in this will be required to detect the defined concepts in the 20,000 images which are used in the photo retrieval task. If you are interested in this, please contact the organizers as we are currently not yet sure how this can be evaluated.
Hierarchy
The images are labelled according to this class hierarchy:
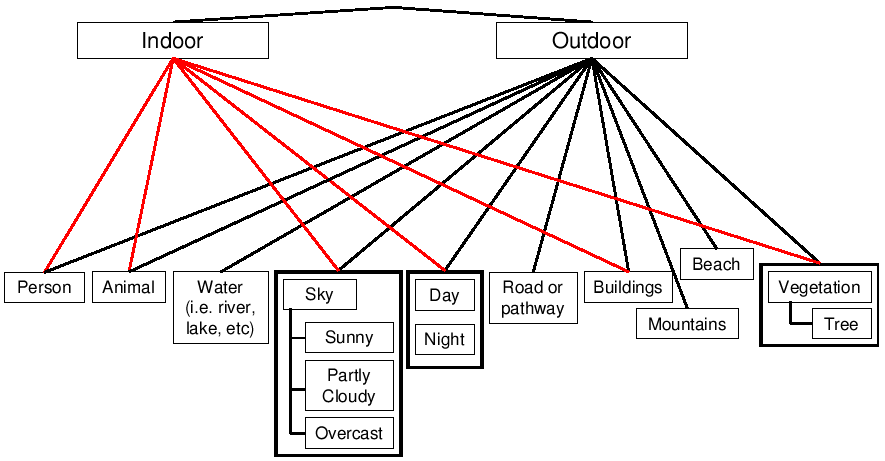
Data
The visual concept detection task will work on a subset of the extended IAPR TC-12 database which is also used for the Photo Retrieval Task of ImageCLEF 2008.
You need to be registered to access these data.
Username and password to access these data is provided upon registration for ImageCLEF 2008.
Training and Test data is now available.
- Training Data
- Training Data Annotation
May 8, 2008, NOTE: Gao Sheng from Singapore found a mistake in the training annotation:
Image 27-27858.jpg should not not annotated to contain the person-concept.
Feel free to change this for your training. - Test Data
Format of the annotation
27-27700.jpg 0 1 0 0 1 0 0 1 1 1 0 0 1 0 0 0 0 27-27704.jpg 0 1 0 1 0 0 0 0 0 1 0 0 1 0 1 0 0 27-27705.jpg 0 1 0 0 1 0 0 1 0 1 0 0 1 0 0 1 0 27-27706.jpg 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 27-27709.jpg 0 1 0 1 0 0 1 0 0 0 0 0 1 0 0 1 0 27-27712.jpg 0 1 0 0 0 0 0 1 0 1 0 0 1 0 1 0 0 ...
The first column gives the filename of the image and the succeeding columns denote presence/absence of the concepts in this order:
0 indoor
1 outdoor
2 person
3 day
4 night
5 water
6 road or pathway
7 vegetation
8 tree
9 mountains
10 beach
11 buildings
12 sky
13 sunny
14 partly cloudy
15 overcast
16 animal
Evaluation
Please note that it is not permitted to use any additional data for training and setup of the systems. If you need test data for system tuning, you need to split the available training data into a training and evaluation set.
We will use equal error rate to evaluate the performance of the individual runs.
Eval Script
As of May 13, 2008, a new evaluation script was released, which can be downloaded here. The new tool is implemented in octave but works also with matlab.
old, partly buggy eval script
Put it into the same directory as the training data annotation, and the list of classes.
Running the program on a file will output the Equal Error Rate for each class. The program requires valid submission files for an arbitrary subset of the training data.
Adding a -roc option will additionally output a set of files to plot with gnuplot.
To run it. 1. Download eval.py
2. download classes.txt
3. download the training data annotation
4. put all these into the same directory
5. then create a file in the format of the submission file and run eval.py
Eval.py will print the EER for the subset of images that are contained in your submission file. You canNOT evaluate submissions files for the test data, since you do not have the annotation of the test data.
Submission
Submission format is equal to the annotation format of the training data, except that you are expected to give some confidence scores for each concept to be present or absent.
That is, you have to submit a file containing the same number of columns, but each number can be an arbitrary floating point number, where higher numbers denote higher security regarding the presence of a particular concept.
The submission site is available now
Annotation for the IAPR database
Additionally we encourage participants to provide us with annotations for all images in the IAPR TC-12 database which we will distribute among the participants of the retrieval task to study the usefulness of visual concept detections for the retrieval of images.
IAPR database is available here
For this we do not put a strict deadline, but will create a repository of submitted annotations. We encourage to submit results as fast as possible but no later than May 15 to allow for proper use in the retrieval task.
Submitted runs are being made available here.
Schedule
Submission of Results: May 15, 0:00h CET, no extension
Organisers
Thomas Deselaers, RWTH Aachen University, Aachen, Germany
Allan Hanbury, Vienna University of Technology Institute of Computer Aided Automation, Pattern Recognition and Image Processing Group, Vienna, Austria
| Attachment | Size |
|---|---|
| 24.16 KB | |
| 2.88 KB | |
| 189 bytes | |
| 11.28 KB |
{kind=link}