- ImageCLEF 2026
- LifeCLEF 2026
- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
PlantCLEF 2016

| News |
| A direct link to the overview of the task: Plant Identification In An Open World (LifeCLEF2016), CLEF 2016 working notes, Goëau H., Joly A., Bonnet P., LifeCLEF 2016 working notes, Evora, Portugal |
| Dataset: The public packages containing all the data of the LifeCLEF 2016 plant retrieval task are now available (including the ground truth, a script for computing the scores, the working notes). You can download it using the following urls: https://lab.plantnet.org/LifeCLEF/PlantCLEF2016/RunFilesToolAndResults.zip https://lab.plantnet.org/LifeCLEF/PlantCLEF2016/PlantCLEF2016Test.tar.gz https://lab.plantnet.org/LifeCLEF/PlantCLEF2015/TrainingPackage/PlantCLE... https://lab.plantnet.org/LifeCLEF/PlantCLEF2015/TestPackage/PlantCLEF201... |
Usage scenario
Crowdsourced initiatives such as iNaturalist, Tela Botanica, Pl@ntNet, or iSpot produce big amounts of biodiversity data that are intended in the long term, to renew today’s ecological monitoring approaches with much more timely and cheaper raw input data. In particular, the scenario that will be addressed within PlantCLEF 2016, is to automatically detect the presence of invasive species in the crowdsourced streams of plant images. A more extensive and precocious detection of the specimens of these species would actually allow a more effective response to the problem (containment measures, mechanical treatments, biocontrol, re-introduction of other species, etc.).
Data collection
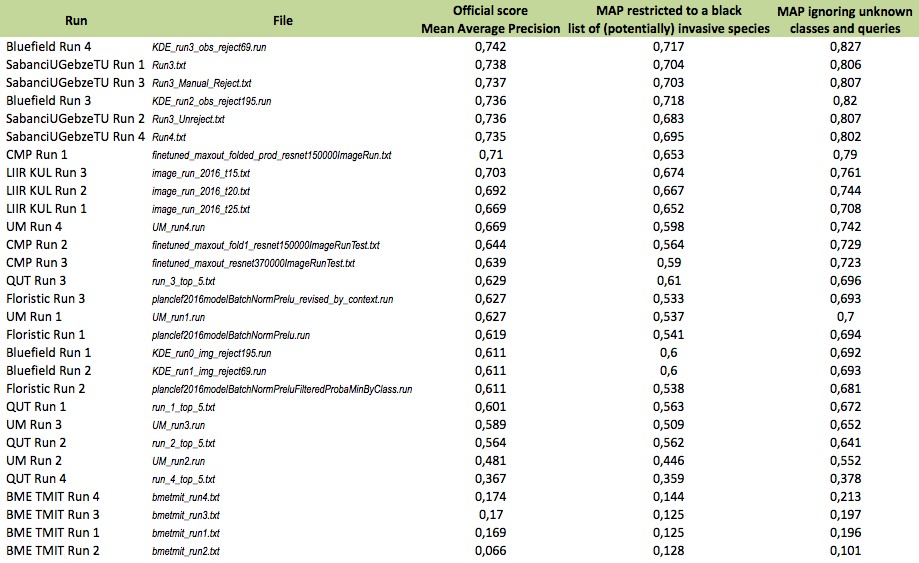
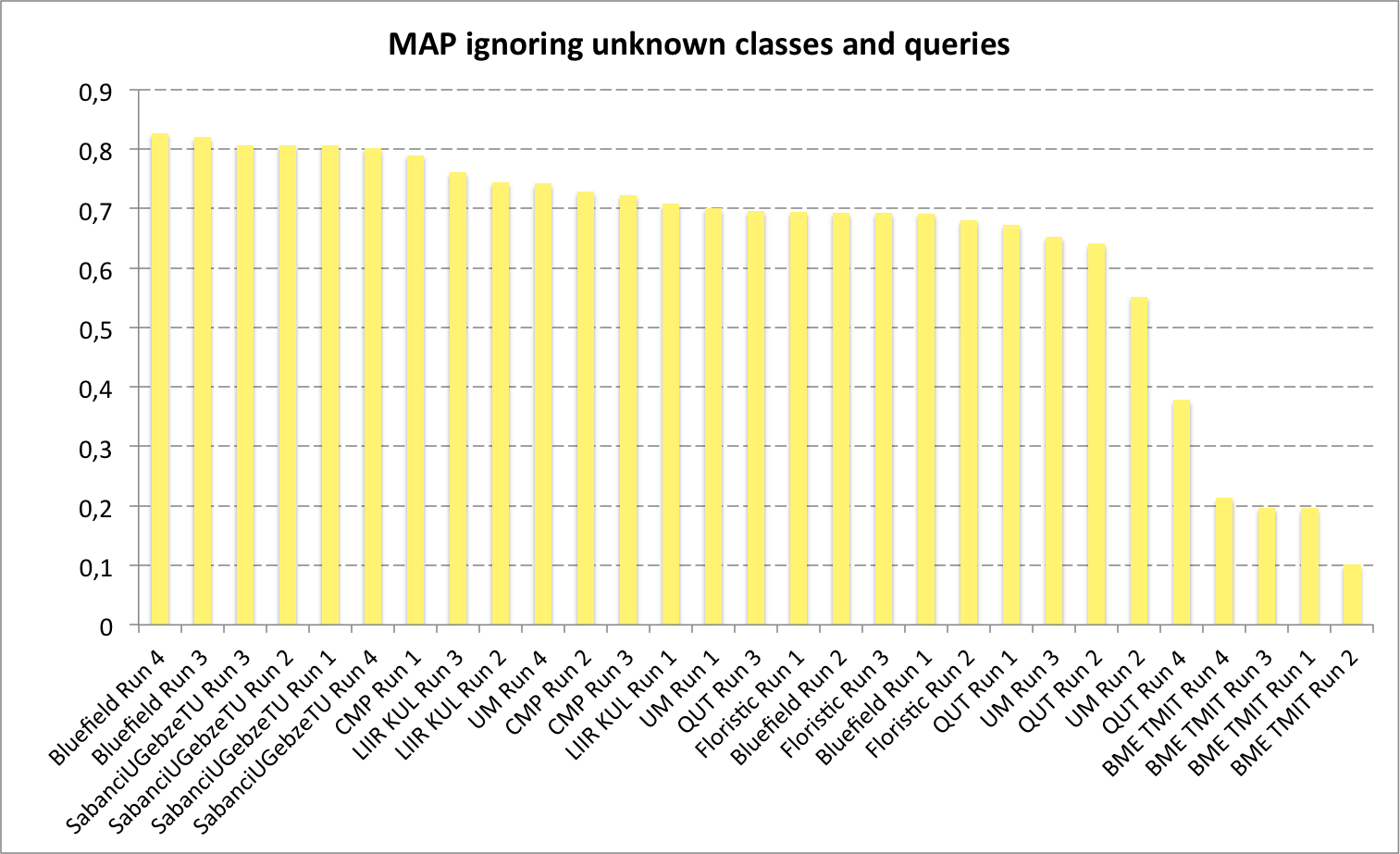
The data to be analysed is a sample of the stream of the raw query images submitted by the users of the popular mobile application Pl@ntNet (iPhone & Androïd) which accounts for several hundreds of thousands of active users submitting about ten of thousands of query images each day. This data is in nature very different from the collaboratively revised and filtered data used within last year’s PlantCLEF challenges. As illustrated through the above samples, it actually contains a much higher level of noise and of unknown objects (either plants that are not in the training set or non-plant objects). The objective is actually to evaluate the challenge of automatically exploiting such crowdsourced data without any validation of the user or intervention of a specialized social network. We therefore created a new annotated dataset based on the image queries that were submitted by authenticated users of the Pl@ntNet mobile application in 2015 (unauthenticated queries had to be removed for copyright issues). A fraction of that queries were already associated to a valid species name because they were explicitly shared by their authors and collaboratively revised. Remaining pictures were distributed to a pool of botanists in charge of manually annotating them either with a valid species name or with newly created tags of their choice (and shared between them). Therefore, 144 new tags were created to qualify the unknown classes such as for instance non-plant objects, legs or hands, UVO (Unidentified Vegetal Object), artificial plants, cactaceae, mushrooms, animals, food, vegetables or more precise names of horticultural plants such as roses, geraniums, ficus, etc. For privacy reasons, we had to remove all images tagged as people (about 1.1% of the tagged queries). In the end, the test set was composed of 8,000 pictures, 4633 labeled with one of the 1000 known classes of the training set, and 3367 labeled as new unknown classes. Among the 4633 images of known species, 366 were tagged as invasive according to a selected list of 26 potentially invasive species. This list was defined by aggregating several sources (such as the National Botanical conservatory, and the Global Invasive Species Programme) and by computing the intersection with the 1000 species of the training set.

As training data, we will provide the PlantCLEF 2015 dataset enriched with the groundtruth annotations of the test images (that were kept secret beforehand). In total, this dataset contains 113,205 pictures of herb, tree and fern specimens belonging to 1,000 species (living in France and neighboring countries). Each image is associated with an xml file containing the taxonomic groundtruth (and in particular the species level ClassId), as well as other meta-data such as the type of view (fruit, flower, entire plant, etc.), the quality rating (social-based), the author name, the observation Id, the date and the geo-loc (for some of the observations).
Task description
The task to be addressed is related to what is called open-set or open-world recognition problems [1,2], i.e. classification problems in which the recognition system has to be robust to unseen categories. Beyond the brute-force classification across the known classes of the training set, a big issue is thus to automatically detect/reject the numerous false positives classification hits that are caused by the unknown classes (i.e. by the distractors). To measure this ability of the evaluated systems, each prediction will have to be associated with a confidence score in [0,1] quantifying the probability that this prediction is true, independently from the other predictions.
More practically, the run file to be submitted has to contain as much lines as the number of predictions, each prediction being composed of an ImageId, a ClassId and a Probability. Each line should have the following format:
<ImageId;ClassId;Probability>
where Probability is a scalar in [0,1] representing the confidence of the system in that recognition (Probability=1 means that the system is very confident). Test images that do not occur in the run file are considered as being rejected for all classes (i.e. Probability=0 for all ClassId's). One single test image might be associated to several predictions.
Each participating group is allowed to submit up to 4 runs built from different methods. Semi-supervised, interactive or crowdsourced approaches are allowed but will be compared independently from fully automatic methods. Any human assistance in the processing of the test queries has therefore to be signaled in the submitted runs.
Participants are allowed to use external training data but at the condition that (i) the experiment is entirely re-produceable, i.e. that the used external ressource is clearly referenced and accessible to any other research group in the world, (ii) participants submit at least one run without external training data so that we can study the contribution of such ressources, (iii) the additional ressource does not contain any of the test observations.
Metric
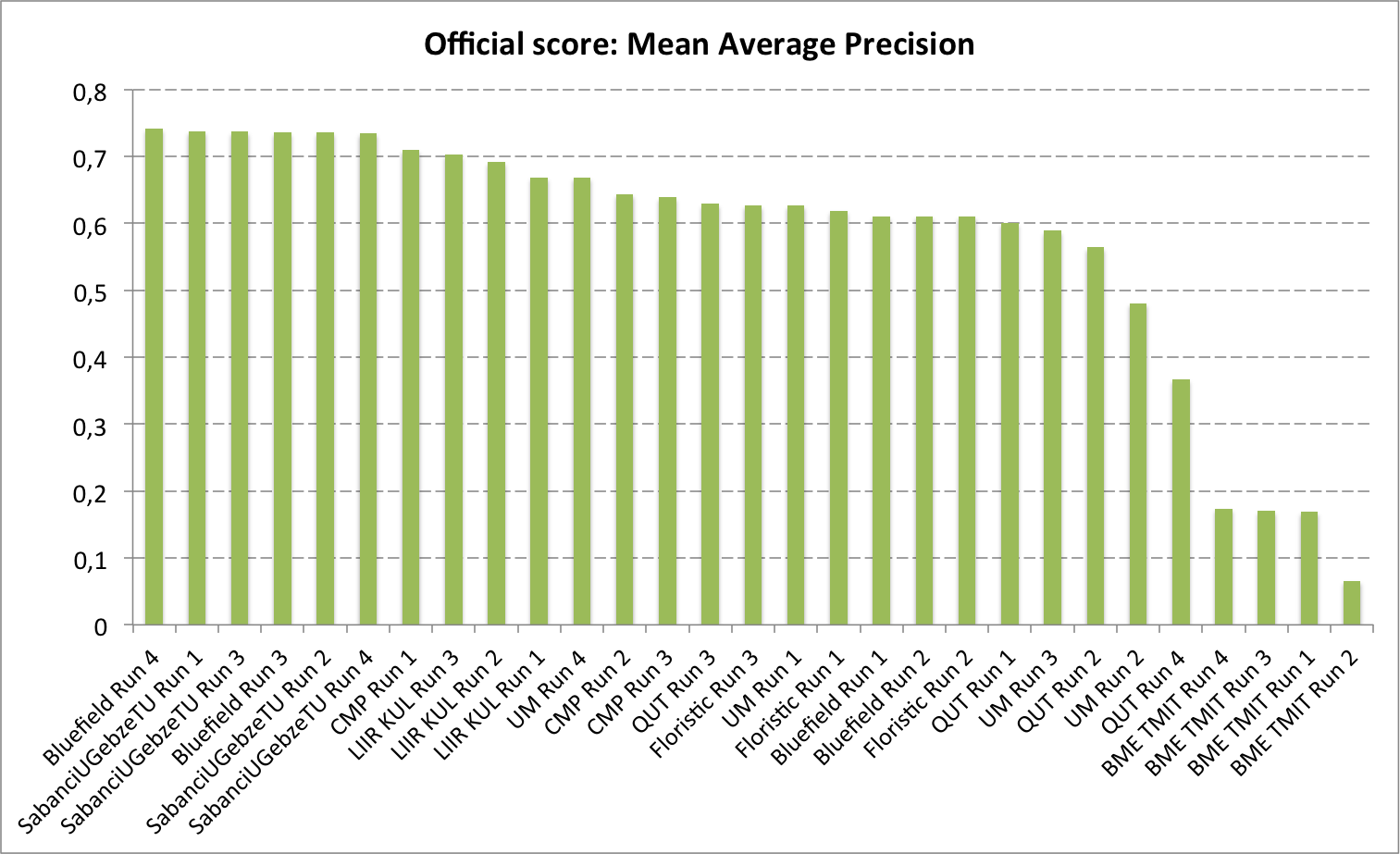
The used metric will be the classification mean Average Precision (mAP), considering each class Ci of the training set as a query. This means that for each class Ci, we will extract from the run file all predictions with ClassId=Ci, rank them by decreasing probability and compute the average precision for that class (i.e. the expectation of the precision when thresholding with the Probability value of each image labeled as Ci in the ground truth). We will then take the mean across all classes. Note that the distractors associated to high Probability values (i.e. false alarms) are likely to highly degrade the mAP.
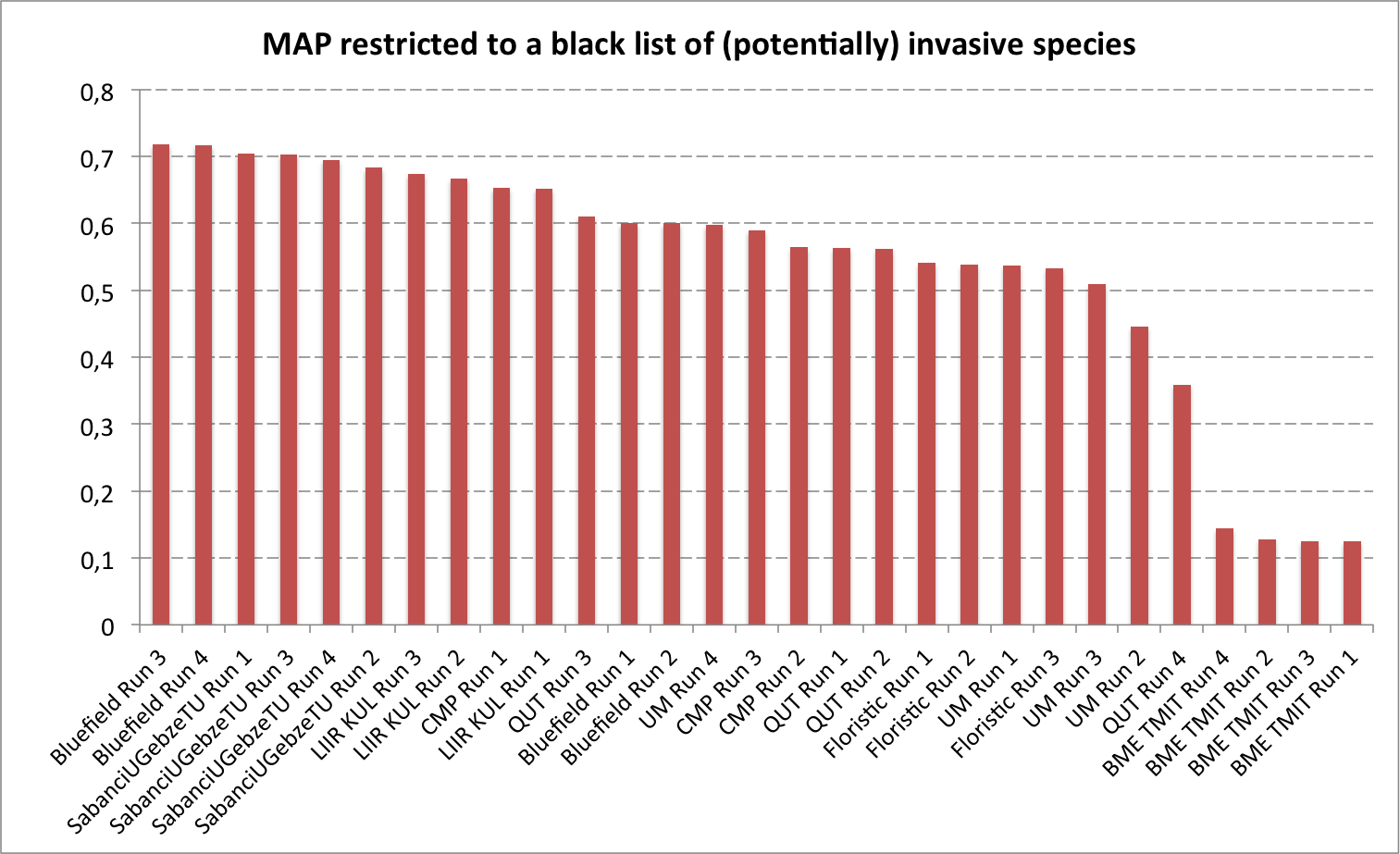
To evaluate more specifically the targeted usage scenario consisting in detecting invasive species, a secondary mAP will be computed by considering as queries only a subset of the species that belongs to a black list of invasive species. To avoid participants tuning their system on that particular scenario and keep our evaluation generalizable to other ones, the black list won't be provided.
Results
A total of 8 participating groups submitted 29 runs. Thanks to all of you for your efforts and your constructive feedbacks regarding the organization.
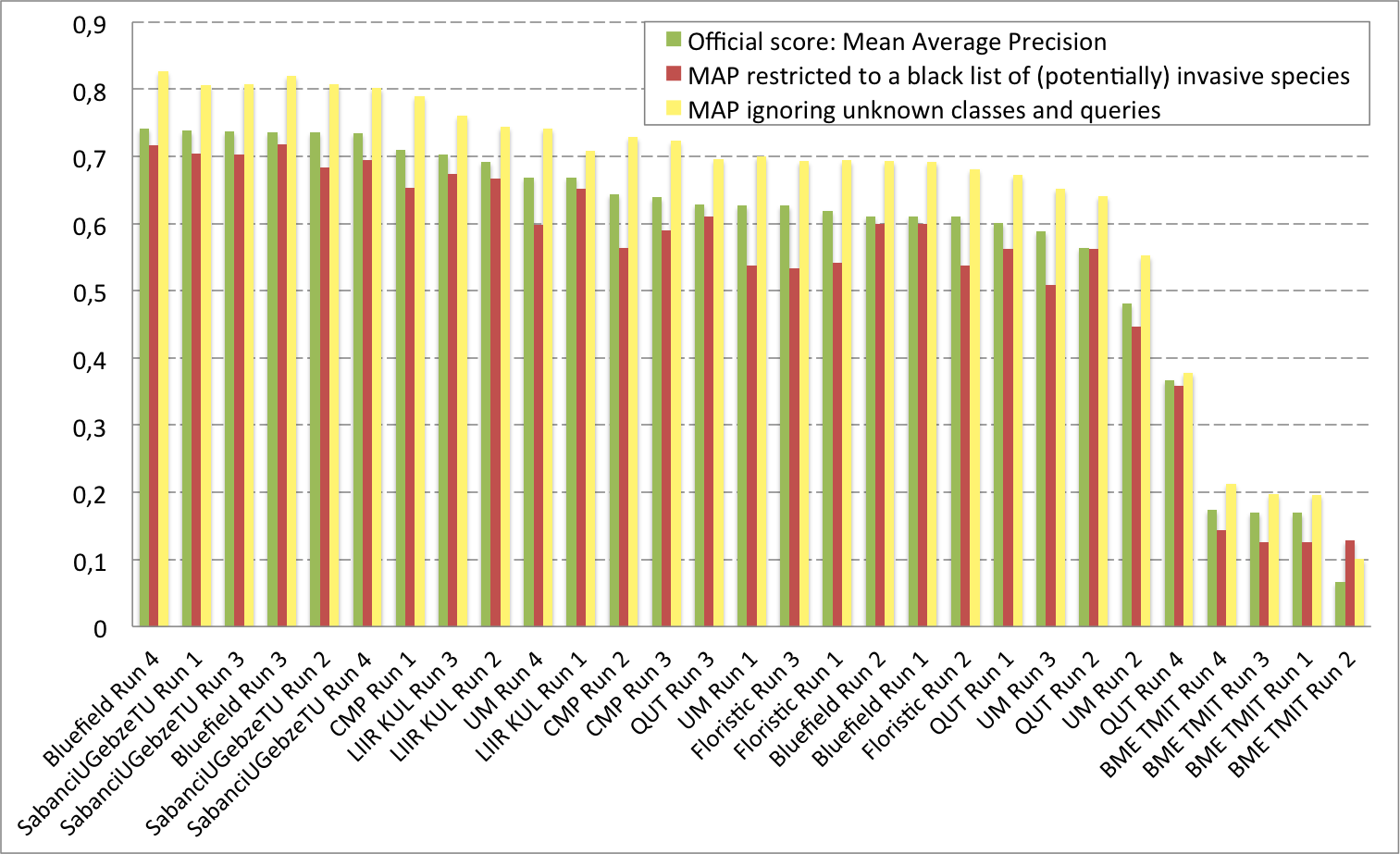
References
[1] Scheirer, W. J., Jain, L. P., & Boult, T. E. (2014). Probability models for open set recognition. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 36(11), 2317-2324.
[2] Bendale, A., & Boult, T. (2014). Towards Open World Recognition. arXiv preprint arXiv:1412.5687.
| Attachment | Size |
|---|---|
| 311.12 KB | |
| 136.83 KB | |
| 137.07 KB | |
| 138.53 KB | |
| 160.48 KB | |
| 147.76 KB |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}