- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
AMIA: Medical task
Changes in 2013!
The ImageCLEF medical task will for the first time organized a workshop outside of Europe; the ImageCLEF meeting is planned at the annual AMIA meeting in the form of a workshop. Posters are still welcome at the CLEF meeting in Valencia.
Citations
- When referring to ImageCLEFmed 2013 task general goals, general results, etc. please cite the following publication:
- Alba García Seco de Herrera, Jayashree Kalpathy-Cramer, Dina Demner-Fushman, Sameer Antani and Henning Müller, Overview of the ImageCLEF 2013 medical tasks, in: CLEF working notes 2013, Valencia, Spain, 2013
-
BibText:
@InProceedings{GKD2013,-
Title = {Overview of the {ImageCLEF} 2013 medical tasks},
Author = {Garc\'ia Seco de Herrera,Alba and Kalpathy--Cramer, Jayashree and Demner Fushman, Dina and Antani, Sameer and M\"uller, Henning},
Booktitle = {Working Notes of {CLEF} 2013 (Cross Language Evaluation Forum)},
Year = {2013},
Month = {September},
Location = {Valencia, Spain}}
- When referring to ImageCLEFmed task in general, please cite the following publication:
- Jayashree Kalpathy-Cramer, Alba García Seco de Herrera, Dina Demner-Fushman, Sameer Antani, Steven Bedrick and Henning Müller, Evaluating Performance of Biomedical Image Retrieval Systems –an Overview of the Medical Image Retrieval task at ImageCLEF 2004-2014 (2014), in: Computerized Medical Imaging and Graphics
-
BibText:
@Article{KGD2014,-
Title = {Evaluating Performance of Biomedical Image Retrieval Systems-- an Overview of the Medical Image Retrieval task at {ImageCLEF} 2004--2014},
Author = {Kalpathy--Cramer, Jayashree and Garc\'ia Seco de Herrera, Alba and Demner--Fushman, Dina and Antani, Sameer and Bedrick, Steven and M\"uller, Henning},
Journal = {Computerized Medical Imaging and Graphics},
Year = {2014}}
News
- 05.07.2013 Details of the special issue and AMIA weorkshop announced.
- 26.02.2013 Test data for the compound figure separation and modality classification are available.
- 25.02.2013 All participants in the medical task can also submit a paper to the CLEF working notes.
- 15.02.2013 Training data for the compound figure separation are available.
- 5.02.2013 A special issue will be organized in Computerized Medical Imaging and Graphics on ImageCLEF 2013.
- 5.02.2013 Training data for the modality classification task has been released.
- 1.02.2013 The database has been released and also topics for the image-based retrieval.
- 15.01.2013 The venue of the medical task in 2013 is decided to be the annual AMIA meeting in the US, more details to follow.
- 12.12.2012 Registration has opened for the medical tasks.
Schedule:
- 12.12.2012: registration opens for all ImageCLEF tasks
- 1.2.2013: data release
- 15.2.2013: training data release for the modality classification and compound figure separation tasks
- 15.2.2013: topic release for the retrieval tasks
- 1.4.2013: submission of runs for the retrieval tasks
- 15.4.2013: submission of runs for the modality classification and compound figure separation tasks
- 1.5.2013: release of results
- 30.11.2013: submission to the special issue on ImageCLEFmed
- 16.11.2013: AMIA 2013 conference Washington DC, USA
The medical retrieval task of ImageCLEF 2013 uses the same subset of PubMed Central containing 305,000 images that was used in 2012.
This task is a use case of the Promise network of excellence and supported by the project.
There will be four types of tasks in 2013:
- Modality Classification:
Previous studies have shown that imaging modality is an important aspect of the image for medical retrieval. In user-studies, clinicians have indicated that modality is one of the most important filters that they would like to be able to limit their search by. Many image retrieval websites (Goldminer, Yottalook) allow users to limit the search results to a particular modality. However, this modality is typically extracted from the caption and is often not correct or present. Studies have shown that the modality can be extracted from the image itself using visual features. Additionally, using the modality classification, the search results can be improved significantly. In 2013, a larger number of compound figures will be present making the task significantly harder but corresponding much more to the reality of biomedical journals. - Compound figure separation:
As up to 40% of the figures in PubMed Central are compound figures, a major step in making the content of the compound figures accessible is the detection of compound figures and then their separation into sub figures that can subsequently be classified into modalities and made available for research.
The task will make available training data with separation labels of the figures, and then a test data set where the labels will be made available after the submission of the results. - Ad-hoc image-based retrieval :
This is the classic medical retrieval task, similar to those in organized in 2005-2012. Participants will be given a set of 30 textual queries with 2-3 sample images for each query. The queries will be classified into textual, mixed and semantic, based on the methods that are expected to yield the best results. - Case-based retrieval:
This task was first introduced in 2009. This is a more complex task, but one that we believe is closer to the clinical workflow. In this task, a case description, with patient demographics, limited symptoms and test results including imaging studies, is provided (but not the final diagnosis). The goal is to retrieve cases including images that might best suit the provided case description. Unlike the ad-hoc task, the unit of retrieval here is a case, not an image. For the purposes of this task, a "case" is a PubMed ID corresponding to the journal article. In the results submissions the article DOI should be used as several articles do not have PubMed IDs nor Article URLs.
Modality classification
The following hierarchy will be used for the modality classification, different form the classes in ImageCLEF 2011 but the same as in 2012.
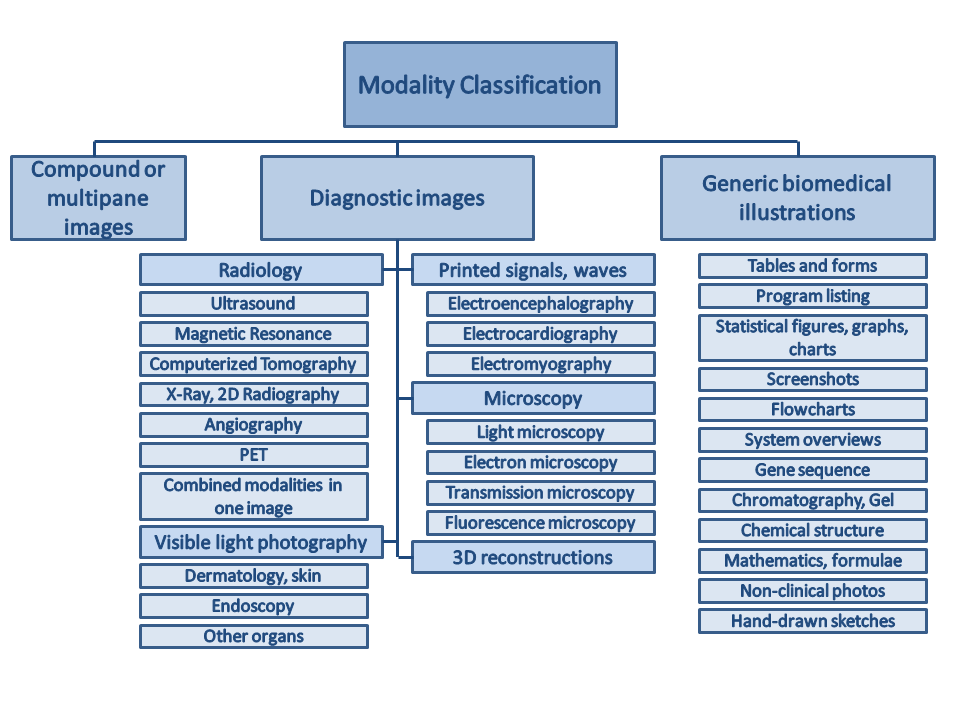
Class codes with descriptions (class codes need to be specified in run files):
([Class code] Description)
- [COMP] Compound or multipane images (1 category)
- [Dxxx] Diagnostic images:
- [DRxx] Radiology (7 categories):
- [DRUS] Ultrasound
- [DRMR] Magnetic Resonance
- [DRCT] Computerized Tomography
- [DRXR] X-Ray, 2D Radiography
- [DRAN] Angiography
- [DRPE] PET
- [DRCO] Combined modalities in one image
- [DVxx] Visible light photography (3 categories):
- [DVDM] Dermatology, skin
- [DVEN] Endoscopy
- [DVOR] Other organs
- [DSxx] Printed signals, waves (3 categories):
- [DSEE] Electroencephalography
- [DSEC] Electrocardiography
- [DSEM] Electromyography
- [DMxx] Microscopy (4 categories):
- [DMLI] Light microscopy
- [DMEL] Electron microscopy
- [DMTR] Transmission microscopy
- [DMFL] Fluorescence microscopy
- [D3DR] 3D reconstructions (1 category)
- [Gxxx] Generic biomedical illustrations (12 categories):
- [GTAB] Tables and forms
- [GPLI] Program listing
- [GFIG] Statistical figures, graphs, charts
- [GSCR] Screenshots
- [GFLO] Flowcharts
- [GSYS] System overviews
- [GGEN] Gene sequence
- [GGEL] Chromatography, Gel
- [GCHE] Chemical structure
- [GMAT] Mathematics, formulae
- [GNCP] Non-clinical photos
- [GHDR] Hand-drawn sketches
Data Download
Our database distribution includes an XML file and a compressed file containing the over 300,000 images of 75'000 articles of the biomedical open access literature.
The login/password for accessing the data is not your personal login/password for the registration system.
In the registration system under collections, details, you can find all information on accessing the data.
Topics
We will provide 30 ad-hoc topics, divided into visual, mixed and semantic topic types.
We will also provide 30 case-based topics, where the retrieval unit is a case, not an image.
Data Submission
Image-based and case-based retrieval
Please ensure that your submissions are compliant with the trec_eval format prior to submission. We will reject any runs that do not meet the required format.
Also, please note that each group is allowed a maximum of 10 runs for image-based and case-based topics each.
The qrels will be distributed among the participants, so further runs can be evaluated for the working notes papers by the participants.
Do not hesitate to ask if you have questions regarding the trec_eval format.
At the time of submission, the following information about each run will be requested. Please let us know if you would like clarifications on how to classify your runs.
1. What was used for the retrieval: Image, text or mixed (both)
2. Was other training data used?
3. Run type: Automatic, Manual, Interactive
4. Query Language
trec_eval format
The format for submitting results is based on the trec_eval program (http://trec.nist.gov/trec_eval/) as follows:
1 1 27431 1 0.567162 OHSU_text_1
1 1 27982 2 0.441542 OHSU_text_1
.............
1 1 52112 1000 0.045022 OHSU_text_1
2 1 43458 1 0.9475 OHSU_text_1
.............
25 1 28937 995 0.01492 OHSU_text_1
where:
- The first column contains the topic number.
- The second column is always 1.
- The third column is the image identifier (IRI) without the extension jpg and without any image path (or the full article DOI for the case-based topics).
- The fourth column is the ranking for the topic (1-1000).
- The fifth column is the score assigned by the system.
- The sixth column is the identifier for the run and should be the same in the entire file.
Several key points for submitted runs are:
- The topic numbers should be consecutive and complete.
- Case-based and image-based topics have to be submitted in separate files.
- The score should be in decreasing order (i.e. the image at the top of the list should have a higher score than images at the bottom of the list).
- Up to (but not necessarily) 1000 images can be submitted for each topic.
- Each topic must have at least one image.
- Each run must be submitted in a single file. Files should be pure text files and not be zipped or otherwise compressed.
Modality classification
The format of the result submission for the modality classification subtask should be the following:
1471-2091-8-12-2 DRUS 0.9
1471-2091-8-29-7 GTAB 1
1471-2105-10-276-8 DMLI 0.4
1471-2105-10-379-3 D3DR 0.8
1471-2105-10-S1-S60-3 COMP 0.9
...
where:
- The first column contains the Image-ID (IRI). This ID does not contain the file format ending and it should not represent a file path.
- The second column is the classcode.
- The third column represents the normalized score (between 0 and 1) that your system assigned to that specific result.
You should also respect the following constraints:
- Each specified image must be part of the collection (dataset).
- An Image cannot be contained more than once.
- At least all images of the testset must be contained in runfile, however it would be nice to have the whole dataset classified.
- Only known classcodes are accepted.
Please note that each group is allowed a maximum of 10 runs.
Compound figure separation
The format of the result submission for the compound figure separation subtask should be an XML file with the following structure :
where:
- The root element is <annotations>.
- The root contains one <annotation> element per image. Each one of these elements must contain :
- A <filename> element with the name of the compound image (including the file extension)
- One or more <object> elements that define the bounding box of each subfigure in the image. Each <object> must contain :
- 4 <point> elements that define the 4 corners of the bounding box. The <point> elements must have two attributes (x and y), which correspond to the horizontal and vertical pixel position, respectively. The preferred order of the points is :
- top-left
- top-right
- bottom-left
- bottom-right
You should also respect the following constraints:
- Each specified image must be part of the collection (dataset).
- An Image cannot appear more than once in a single XML results file.
- All the images of the testset must be contained in the runfile.
- The resulting XML file MUST validate against the XSD schema that will be provided.
Evaluation
Compound figure separation
This section provides an overview of the evaluation method used for the compound figure separation subtask.
Consider the following figure, which is separated into 3 subfigures :

The basic idea of the evaluation for a figure is the following :
- For each subfigure in the ground truth, the application will look for the best matching subfigure in the submitted run data (which will be called "candidate" from now on)
- Each subfigure is worth 1 point. If all the subfigures in the ground truth are successfully mapped to one corresponding subfigure in the candidate (and no extra subfigures are present), the result will be 3 points, which normalized to the number of figures, yields a score of 1.0
Example of a perfect scoring candidate for the base figure above :

As you can see, there is exactly one candidate subfigure for every subfigure defined in the ground truth. This leads us to the next set of rules :
- The separators don't always match the real size of the subfigures (there may be blank space around them). Therefore, the main metric used for evaluation is the overlap between a candidate subfigure and the ground truth.
Overlap ratio is measured with respect to the candidate. - To be considered a valid match, the overlap between a candidate subfigure and a subfigure from the ground truth must be at least 66%
- Only one candidate subfigure can be assigned to each of the subfigures from the ground truth. The subfigure with the biggest overlap will be considered in case of multiple possibilities
Here is another example :

In this candidate figure, only one of the 3 subfigures was identified correctly. Indeed, the red subfigure candidate doesn't have an overlap of >=66% with either of the other two subfigures, so it remains an "orphan".
Here is another example that will illustrate the last rule :

This last figure shows what happens when extra subfigures are detected in the candidate :
- The maximum score is modified to correspond to the number of candidate subfigures. The normalization factor used to compute the score will be the maximum between the number of subfigures in the ground truth and the number of candidate subfigures
- In this case, all 3 subfigures from the ground truth are correctly matched, but two superfluous figures are present (hence a score of 3/5)
Bonus example :

Having a single candidate subfigure spanning the whole image will often result in a score of 0.0, since the subfigure won't be contained to >=66% in any of the ground truth subfigures.
Results
Modality classification
| Runs | Group name | Run type | Correctly classified in % |
| Mixed | |||
| IBM_modality_run8 | IBM | Automatic | 81.68 |
| results_mixed_finki_run3 | FINKI | Automatic | 78.04 |
| All | Center for Informatics and Information Technologies | Automatic | 72.92 |
| IBM_modality_run9 | IBM | Automatic | 69.82 |
| medgift2013_mc_mixed_k8 | medGIFT | Automatic | 69.63 |
| medgift2013_mc_mixed_sem_k8 | medGIFT | Automatic | 69.63 |
| nlm_mixed_using_2013_visual_classification_2 | ITI | Automatic | 69.28 |
| nlm_mixed_using_2013_visual_classification_1 | ITI | Automatic | 68.74 |
| nlm_mixed_hierarchy | ITI | Automatic | 67.31 |
| nlm_mixed_using_2012_visual_classification | ITI | Automatic | 67.07 |
| DEMIR_MC_5 | DEMIR | Automatic | 64.60 |
| DEMIR_MC_3 | DEMIR | Automatic | 64.48 |
| DEMIR_MC_6 | DEMIR | Automatic | 64.09 |
| DEMIR_MC_4 | DEMIR | Automatic | 63.67 |
| medgift2013_mc_mixed_exp_sep_sem_k21 | medGIFT | Automatic | 62.27 |
| IPL13_mod_cl_mixed_r2 | IPL | Automatic | 61.03 |
| IBM_modality_run10 | IBM | Automatic | 60.34 |
| IPL13_mod_cl_mixed_r3 | IPL | Automatic | 58.98 |
| medgift2013_mc_mixed_exp_k21 | medGIFT | Automatic | 47.83 |
| medgift2013_mc_mixed_exp_sem_k21 | medGIFT | Automatic | 47.83 |
| All_NoComb | Center for Informatics and Information Technologies | Automatic | 44.61 |
| IPL13_mod_cl_mixed_r1 | IPL | Automatic | 09.56 |
| Textual | |||
| IBM_modality_run1 | IBM | Automatic | 64.17 |
| results_text_finki_run2 | FINKI | Automatic | 63.71 |
| DEMIR_MC_1 | DEMIR | Automatic | 62.70 |
| DEMIR_MC_2 | DEMIR | Automatic | 62.70 |
| words | Center for Informatics and Information Technologies | Automatic | 62.35 |
| medgift2013_mc_text_k8 | medGIFT | Automatic | 62.04 |
| nlm_textual_only_flat | ITI | Automatic | 51.23 |
| IBM_modality_run2 | IBM | Automatic | 39.07 |
| words_noComb | Center for Informatics and Information Technologies | Automatic | 32.80 |
| IPL13_mod_cl_textual_r1 | IPL | Automatic | 09.02 |
| Visual | |||
| IBM_modality_run4 | IBM | Automatic | 80.79 |
| IBM_modality_run5 | IBM | Automatic | 80.01 |
| IBM_modality_run6 | IBM | Automatic | 79.82 |
| IBM_modality_run7 | IBM | Automatic | 78.89 |
| results_visual_finki_run1 | FINKI | Automatic | 77.14 |
| results_visual_compound_finki_run4 | FINKI | Automatic | 76.29 |
| IBM_modality_run3 | IBM | Automatic | 75.94 |
| sari_modality_baseline | MIILab | Automatic | 66.46 |
| sari_modality_CCTBB_DRxxDict | MIILab | Automatic | 65.60 |
| medgift2013_mc_5f | medGIFT | Automatic | 63.78 |
| nlm_visual_only_hierarchy | ITI | Automatic | 61.50 |
| medgift2013_mc_5f_exp_separate_k21 | medGIFT | Automatic | 61.03 |
| medgift2013_mc_5f_separate | medGIFT | Automatic | 59.25 |
| CEDD_FCTH | Center for Informatics and Information Technologies | Automatic | 57.62 |
| IPL13_mod_cl_visual_r2 | IPL | Automatic | 52.05 |
| medgift2013_mc_5f_exp_k8 | medGIFT | Automatic | 45.42 |
| IPL13_mod_cl_visual_r3 | IPL | Automatic | 43.33 |
| CEDD_FCTH_NoComb | Center for Informatics and Information Technologies | Automatic | 32.49 |
| IPL13_mod_cl_visual_r1 | IPL | Automatic | 06.19 |
Compound figure separation
| Runs | Group name | Run type | Correctly classified in % |
| ImageCLEF2013_CompoundFigureSeparation_HESSO_CFS | medGIFT | Visual | 84.64 |
| nlm_multipanel_separation | ITI | Mixed | 69.27 |
| fcse-final-noempty | FINKI | 68.59 | |
| ImageCLEF2013_CompoundFigureSeparation_HESSO_REGIONDETECTOR_SCALE50_STANDARD | medGIFT | Visual | 46.82 |
Ad-hoc image-based retrieval
| Runid | Retrieval type | MAP | GM-MAP | bpref | P10 | P30 |
| nlm-se-image-based-mixed | Mixed | 0.3196 | 0.1018 | 0.2983 | 0.3886 | 0.2686 |
| Txt_Img_Wighted_Merge | Mixed | 0.3124 | 0.0971 | 0.3014 | 0.3886 | 0.279 |
| Merge_RankToScore_weighted | Mixed | 0.312 | 0.1001 | 0.295 | 0.3771 | 0.2686 |
| Txt_Img_Wighted_Merge | Mixed | 0.3086 | 0.0942 | 0.2938 | 0.3857 | 0.259 |
| Merge_RankToScore_weighted | Mixed | 0.3032 | 0.0989 | 0.2872 | 0.3943 | 0.2705 |
| medgift_mixed_rerank_close | Mixed | 0.2465 | 0.0567 | 0.2497 | 0.3229 | 0.2524 |
| medgift_mixed_rerank_nofilter | Mixed | 0.2375 | 0.0539 | 0.2307 | 0.2886 | 0.2238 |
| medgift_mixed_weighted_nofilter | Mixed | 0.2309 | 0.0567 | 0.2197 | 0.28 | 0.2181 |
| medgift_mixed_rerank_prefix | Mixed | 0.2271 | 0.047 | 0.2289 | 0.2886 | 0.2362 |
| DEMIR3 | Mixed | 0.2168 | 0.0345 | 0.2255 | 0.3143 | 0.1914 |
| DEMIR10 | Mixed | 0.1583 | 0.0292 | 0.1775 | 0.2771 | 0.1867 |
| DEMIR7 | Mixed | 0.0225 | 0.0003 | 0.0355 | 0.0543 | 0.0543 |
| nlm-se-image-based-textual | Textual | 0.3196 | 0.1018 | 0.2982 | 0.3886 | 0.2686 |
| IPL13_textual_r6 | Textual | 0.2542 | 0.0422 | 0.2479 | 0.3314 | 0.2333 |
| BM25b1.1 | Textual | 0.2507 | 0.0443 | 0.2497 | 0.32 | 0.2238 |
| finki | Textual | 0.2479 | 0.0515 | 0.2336 | 0.3057 | 0.2181 |
| medgift_text_close | Textual | 0.2478 | 0.0587 | 0.2513 | 0.3114 | 0.241 |
| finki | Textual | 0.2464 | 0.0508 | 0.2338 | 0.3114 | 0.22 |
| BM25b1.1 | Textual | 0.2435 | 0.043 | 0.2424 | 0.3314 | 0.2248 |
| BM25b1.1 | Textual | 0.2435 | 0.043 | 0.2424 | 0.3314 | 0.2248 |
| IPL13_textual_r4 | Textual | 0.24 | 0.0607 | 0.2373 | 0.2857 | 0.2143 |
| IPL13_textual_r1 | Textual | 0.2355 | 0.0583 | 0.2307 | 0.2771 | 0.2095 |
| IPL13_textual_r8 | Textual | 0.2355 | 0.0579 | 0.2358 | 0.28 | 0.2171 |
| IPL13_textual_r8b | Textual | 0.2355 | 0.0579 | 0.2358 | 0.28 | 0.2171 |
| IPL13_textual_r3 | Textual | 0.2354 | 0.0604 | 0.2294 | 0.2771 | 0.2124 |
| IPL13_textual_r2 | Textual | 0.235 | 0.0583 | 0.229 | 0.2771 | 0.2105 |
| FCT_SOLR_BM25L_MSH | Textual | 0.2305 | 0.0482 | 0.2316 | 0.2971 | 0.2181 |
| medgift_text_nofilter | Textual | 0.2281 | 0.053 | 0.2269 | 0.2857 | 0.2133 |
| IPL13_textual_r5 | Textual | 0.2266 | 0.0431 | 0.2285 | 0.2743 | 0.2086 |
| medgift_text_prefix | Textual | 0.2226 | 0.047 | 0.2235 | 0.2943 | 0.2305 |
| FCT_SOLR_BM25L | Textual | 0.22 | 0.0476 | 0.228 | 0.2657 | 0.2114 |
| DEMIR9 | Textual | 0.2003 | 0.0352 | 0.2158 | 0.2943 | 0.1952 |
| DEMIR1 | Textual | 0.1951 | 0.0289 | 0.2036 | 0.2714 | 0.1895 |
| DEMIR6 | Textual | 0.1951 | 0.0289 | 0.2036 | 0.2714 | 0.1895 |
| SNUMedinfo11 | Textual | 0.18 | 0.0266 | 0.1866 | 0.2657 | 0.1895 |
| DEMIR8 | Textual | 0.1578 | 0.0267 | 0.1712 | 0.2714 | 0.1733 |
| finki | Textual | 0.1456 | 0.0244 | 0.148 | 0.2 | 0.1286 |
| IBM_image_run_1 | Textual | 0.0848 | 0.0072 | 0.0876 | 0.1514 | 0.1038 |
| DEMIR4 | Visual | 0.0185 | 0.0005 | 0.0361 | 0.0629 | 0.0581 |
| medgift_visual_nofilter | Visual | 0.0133 | 0.0004 | 0.0256 | 0.0571 | 0.0448 |
| medgift_visual_close | Visual | 0.0132 | 0.0004 | 0.0256 | 0.0543 | 0.0438 |
| medgift_visual_prefix | Visual | 0.0129 | 0.0004 | 0.0253 | 0.06 | 0.0467 |
| IPL13_visual_r6 | Visual | 0.0119 | 0.0003 | 0.0229 | 0.0371 | 0.0286 |
| image_latefusion_merge | Visual | 0.011 | 0.0003 | 0.0207 | 0.0257 | 0.0314 |
| DEMIR5 | Visual | 0.011 | 0.0004 | 0.0257 | 0.04 | 0.0448 |
| image_latefusion_merge_filter | Visual | 0.0101 | 0.0003 | 0.0244 | 0.0343 | 0.0324 |
| latefusuon_accuracy_merge | Visual | 0.0092 | 0.0003 | 0.0179 | 0.0314 | 0.0286 |
| IPL13_visual_r3 | Visual | 0.0087 | 0.0003 | 0.0173 | 0.0286 | 0.0257 |
| sari_SURFContext_HI_baseline | Visual | 0.0086 | 0.0003 | 0.0181 | 0.0429 | 0.0352 |
| IPL13_visual_r8 | Visual | 0.0086 | 0.0003 | 0.0173 | 0.0286 | 0.0257 |
| IPL13_visual_r5 | Visual | 0.0085 | 0.0003 | 0.0178 | 0.0314 | 0.0257 |
| IPL13_visual_r1 | Visual | 0.0083 | 0.0002 | 0.0176 | 0.0314 | 0.0257 |
| IPL13_visual_r4 | Visual | 0.0081 | 0.0002 | 0.0182 | 0.04 | 0.0305 |
| IPL13_visual_r7 | Visual | 0.0079 | 0.0003 | 0.0175 | 0.0257 | 0.0267 |
| FCT_SEGHIST_6x6_LBP | Visual | 0.0072 | 0.0001 | 0.0151 | 0.0343 | 0.0267 |
| IPL13_visual_r2 | Visual | 0.0071 | 0.0001 | 0.0162 | 0.0257 | 0.0257 |
| IBM_image_run_min_min | Visual | 0.0062 | 0.0002 | 0.016 | 0.0286 | 0.0267 |
| DEMIR2 | Visual | 0.0044 | 0.0002 | 0.0152 | 0.0229 | 0.0229 |
| SNUMedinfo13 | Visual | 0.0043 | 0.0002 | 0.0126 | 0.0229 | 0.0181 |
| SNUMedinfo12 | Visual | 0.0033 | 0.0001 | 0.0153 | 0.0257 | 0.0219 |
| IBM_image_run_Mnozero17 | Visual | 0.003 | 0.0001 | 0.0089 | 0.02 | 0.0105 |
| SNUMedinfo14 | Visual | 0.0023 | 0.0002 | 0.009 | 0.0171 | 0.0124 |
| SNUMedinfo15 | Visual | 0.0019 | 0.0002 | 0.0074 | 0.0086 | 0.0114 |
| IBM_image_run_Mavg7 | Visual | 0.0015 | 0.0001 | 0.0082 | 0.0171 | 0.0114 |
| IBM_image_run_Mnozero11 | Visual | 0.0008 | 0 | 0.0045 | 0.0057 | 0.0095 |
| nlm-se-image-based-visual | Visual | 0.0002 | 0 | 0.0021 | 0.0029 | 0.001 |
Case-based retrieval
| Runid | Retrieval type | MAP | GM-MAP | bpref | P10 | P30 |
| FCT_CB_MM_rComb | Mixed | 0.1608 | 0.0779 | 0.1426 | 0.18 | 0.1257 |
| medgift_mixed_nofilter_casebased | Mixed | 0.1467 | 0.0883 | 0.1318 | 0.1971 | 0.1457 |
| nlm-se-case-based-mixed | Mixed | 0.0886 | 0.0303 | 0.0926 | 0.1457 | 0.0962 |
| FCT_CB_MM_MNZ | Mixed | 0.0794 | 0.0035 | 0.085 | 0.1371 | 0.081 |
| SNUMedinfo9 | Textual | 0.2429 | 0.1163 | 0.2417 | 0.2657 | 0.1981 |
| SNUMedinfo8 | Textual | 0.2389 | 0.1279 | 0.2323 | 0.2686 | 0.1933 |
| SNUMedinfo5 | Textual | 0.2388 | 0.1266 | 0.2259 | 0.2543 | 0.1857 |
| SNUMedinfo6 | Textual | 0.2374 | 0.1112 | 0.2304 | 0.2486 | 0.1933 |
| FCT_LUCENE_BM25L_MSH_PRF | Textual | 0.2233 | 0.1177 | 0.2044 | 0.26 | 0.18 |
| SNUMedinfo4 | Textual | 0.2228 | 0.1281 | 0.2175 | 0.2343 | 0.1743 |
| SNUMedinfo1 | Textual | 0.221 | 0.1208 | 0.1952 | 0.2343 | 0.1619 |
| SNUMedinfo2 | Textual | 0.2197 | 0.0996 | 0.1861 | 0.2257 | 0.1486 |
| SNUMedinfo7 | Textual | 0.2172 | 0.1266 | 0.2116 | 0.2486 | 0.1771 |
| FCT_LUCENE_BM25L_PRF | Textual | 0.1992 | 0.0964 | 0.1874 | 0.2343 | 0.1781 |
| SNUMedinfo10 | Textual | 0.1827 | 0.1146 | 0.1749 | 0.2143 | 0.1581 |
| HES-SO-VS_FULLTEXT_LUCENE | Textual | 0.1791 | 0.1107 | 0.163 | 0.2143 | 0.1581 |
| SNUMedinfo3 | Textual | 0.1751 | 0.0606 | 0.1572 | 0.2114 | 0.1286 |
| ITEC_FULLTEXT | Textual | 0.1689 | 0.0734 | 0.1731 | 0.2229 | 0.1552 |
| ITEC_FULLPLUS | Textual | 0.1688 | 0.074 | 0.172 | 0.2171 | 0.1552 |
| ITEC_FULLPLUSMESH | Textual | 0.1663 | 0.0747 | 0.1634 | 0.22 | 0.1667 |
| ITEC_MESHEXPAND | Textual | 0.1581 | 0.071 | 0.1635 | 0.2229 | 0.1686 |
| IBM_run_1 | Textual | 0.1573 | 0.0296 | 0.1596 | 0.1571 | 0.1057 |
| IBM_run_3 | Textual | 0.1573 | 0.0371 | 0.139 | 0.1943 | 0.1276 |
| IBM_run_3 | Textual | 0.1482 | 0.0254 | 0.1469 | 0.2 | 0.141 |
| IBM_run_2 | Textual | 0.1476 | 0.0308 | 0.1363 | 0.2086 | 0.1295 |
| IBM_run_1 | Textual | 0.1403 | 0.0216 | 0.138 | 0.1829 | 0.1238 |
| IBM_run_2 | Textual | 0.1306 | 0.0153 | 0.134 | 0.2 | 0.1276 |
| nlm-se-case-based-textual | Textual | 0.0885 | 0.0303 | 0.0926 | 0.1457 | 0.0962 |
| DirichletLM_mu2500.0_Bo1bfree_d_3_t_10 | Textual | 0.0632 | 0.013 | 0.0648 | 0.0857 | 0.0676 |
| DirichletLM_mu2500.0_Bo1bfree_d_3_t_10 | Textual | 0.0632 | 0.013 | 0.0648 | 0.0857 | 0.0676 |
| finki | Textual | 0.0448 | 0.0115 | 0.0478 | 0.0714 | 0.0629 |
| finki | Textual | 0.0448 | 0.0115 | 0.0478 | 0.0714 | 0.0629 |
| DirichletLM_mu2500.0 | Textual | 0.0438 | 0.0112 | 0.056 | 0.0829 | 0.0581 |
| DirichletLM_mu2500.0 | Textual | 0.0438 | 0.0112 | 0.056 | 0.0829 | 0.0581 |
| finki | Textual | 0.0376 | 0.0105 | 0.0504 | 0.0771 | 0.0562 |
| finki | Textual | 0.0376 | 0.0105 | 0.0504 | 0.0771 | 0.0562 |
| BM25b25.0 | Textual | 0.0049 | 0.0005 | 0.0076 | 0.0143 | 0.0105 |
| BM25b25.0 | Textual | 0.0049 | 0.0005 | 0.0076 | 0.0143 | 0.0105 |
| BM25b25.0_Bo1bfree_d_3_t_10 | Textual | 0.0048 | 0.0005 | 0.0071 | 0.0143 | 0.0105 |
| BM25b25.0_Bo1bfree_d_3_t_10 | Textual | 0.0048 | 0.0005 | 0.0071 | 0.0143 | 0.0105 |
| FCT_SEGHIST_6x6_LBP | Visual | 0.0281 | 0.0009 | 0.0335 | 0.0429 | 0.0238 |
| medgift_visual_nofilter_casebased | Visual | 0.0029 | 0.0001 | 0.0035 | 0.0086 | 0.0067 |
| medgift_visual_close_casebased | Visual | 0.0029 | 0.0001 | 0.0036 | 0.0086 | 0.0076 |
| medgift_visual_prefix_casebased | Visual | 0.0029 | 0.0001 | 0.0036 | 0.0086 | 0.0067 |
| nlm-se-case-based-visual | Visual | 0.0008 | 0.0001 | 0.0044 | 0.0057 | 0.0057 |
Organizers
- Henning Müller, HES-SO, Switzerland
- Jayashree Kalpathy-Cramer, Harvard University, USA
- Dina Demner-Fushman, National Library of Medicine, USA
- Sameer Antani, National Library of Medicine, USA
- Alba García Seco de Herrera, HES-SO, Switzerland