- ImageCLEF 2026
- LifeCLEF 2026
- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
Bird task

Context
The general public as well as professionals like park rangers, ecology consultants, fishers or, of course, the ornithologists themselves might actually be users of an automated bird identifying system, typically in the context of wider initiatives related to ecological surveillance or biodiversity conservation. Using audio records rather than bird pictures is justified by current practices. Birds are actually not easy to photograph as they are most of the time hidden, perched high in a tree or frightened by human presence, whereas audio calls and songs have proved to be easier to collect and much more discriminant. The organization of this task is supported by Xeno-Canto foundation for nature sounds and the French projects Pl@ntNet (INRIA, CIRAD, Tela Botanica) and SABIOD Mastodons.
![]()
![]()
![]()
Task overview
The task will be focused on bird identification based on different types of audio records over 501 species from South America centered on Brazil. Additional information includes contextual meta-data (author, date, locality name, comment, quality rates). The main originality of this data is that it was specifically built through a citizen sciences initiative conducted by Xeno-canto, an international social network of amateur and expert ornithologists. This makes the task closer to the conditions of a real-world application: (i) audio records of the same species are coming from distinct birds living in distinct areas (ii) audio records by different users that might not used the same combination of microphones and portable recorders (iii) audio records are taken at different periods in the year and different hours of a day involving different background noise (other bird species, insect chirping, etc).
Dataset
The dataset will be built from the outstanding Xeno-canto collaborative database (http://www.xeno-canto.org/) involving at the time of writing more than 140k audio records covering 8700 bird species observed all around the world thanks to the active work of more than 1400 contributors.
The subset of Xeno-canto data that will be used for the first year of the task will contain 14027 audio recordings belonging to 501 bird species in Brazil area, i.e. the ones having the more recordings in Xeno-canto database. The amount of 501 classes will clearly go one step further current benchmarks (80 species max) and foster brave new techniques. On the other side, the task will remain feasible with current approaches in terms of the number of records per species and the required hardware to process that data. Detailed statistics are the following:
- minimally 15 recordings per species (maximum 91)
- minimally 10 different recordists, maximally 42, per species.
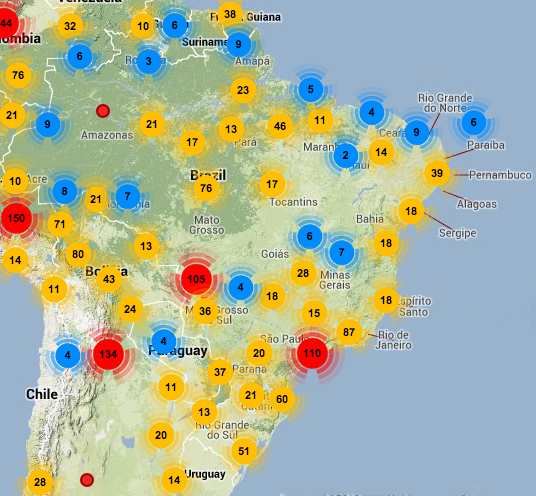
Audio records of the Xeno-canto dataset centered on Brazil (13/11/2013).
Before we release this BirdCLEF2014 dataset, sample records can be easily found on Xeno-canto website:
http://www.xeno-canto.org/
Please DO NOT download the whole Xeno-canto data yourself by using their API. Their system is actually not calibrated to support such massive access and they will provide us specific links to download the training data. Please also notice that, to allow a fair evaluation, it will be strictly forbidden to use the online resources of Xeno-canto as training data because some of them might be used as queries in the official test set of the task. More generally, it will be forbidden to use any external training data to enrich the provided one. Many Xeno-canto contents are actually circulating freely on the web and we could not guaranty that the data crawled by some participants does not include some of the records we will use in the test set.
Audio records are associated to various metadata such as the type of sound (call, song, alarm, flight, etc.), the date and localization of the observations (from which rich statistics on species distribution can be derived), some textual comments of the authors, multilingual common names and collaborative quality ratings. The available metadata for each recording includes:
- MediaId: the audio record ID
- FileName: the (normalized) audio record filename
- ClassId: the class ID that must be used as ground-truth
- Species the species name
- Genus: the name of the Genus, one level above the Species in the taxonomical hierarchy used by Xeno-canto
- Family: the name of the Family, two levels above the Species in the taxonomical hierarchy used by Xeno-canto
- Sub-species: (if available) the name of the sub-species, one level under the Species in the taxonomical hierarchy used by Xeno-canto
- VernacularNames: (if available) english common name(s)
- BackgroundSpecies: latin (Genus species) names of other audible species eventually mentioned by the recordist
- Date: (if available) the date when the bird was observed
- Time: (if available) the time when the bird was observed
- Quality: the (round up) average of the user ratings on audio record quality
- Locality: (if available) the locality name, most of the time a town
- Latitude & Longitude
- Elevation (altitude in meters)
- Author: name of the author of the record,
- AuthorID: id of the author of the record,
- Audio Content: comma-separated list of sound types such as 'call' or 'song', free-form
- Comments: free comments from the recordists
Audio recordings pre-processing and features extraction
In order to avoid any bias in the evaluation related to the used recording devices, the whole audio data has been normalized by Univ. Toulon Dyni team: normalization of the bandwith / frequency sample to 44.1 kHz, .wav format (16 bits). They also provide audio features for both training and test recordings that could be used by any participant, based on Mel Filter Cepstral Coefficients features optimized for bird calls. They are similar than in the previous bird classification challenges ICML4B 2013 and NIPS4B 2013, allowing interesting comparisons. Therefore, 16 MFCC (first coeff = log energy) are computed on windows of 11.6 ms, each 3.9 ms. We derive their speed and acceleration, yielding to one line of 16*3 features per frame. Scripts are detailed at http://sabiod.org/nips4b/ .
Task description
The task will be evaluated as a bird species retrieval task. A part of the collection will be delivered as a training set available a couple of months before the remaining data is delivered. The goal will be to retrieve the singing species among the top-k returned for each of the undetermined observation of the test set. Participants will be allowed to use any of the provided metadata complementary to the audio content.
Training and test data
As it was mentioned below above-said, the "Background" field in the Metadata may indicate if there are some other species identified in the background like for this observation or not even if Xeno-canto encourage to identify them. Some audio records may also not contain at all a dominant bird species like in this example.
The training dataset will contain only audio records with a dominant bird species, with or without other identified bird species in the background. Participants are free to use these background informations or not.
The test datatest will contain the same type of audio records but with purged background informations and comments which can potentially also include some species names. More precisely, the purged test xml files will only include:
- MediaId: the audio record ID
- FileName: the (normalized) audio record filename
- Date: (if available) the date when the bird was observed
- Time: (if available) the time when the bird was observed
- Locality: (if available) the locality name, most of the time a town
- Latitude & Longitude
- Elevation (altitude in meters)
- Author: name of the author of the record,
- AuthorID: id of the author of the record
The training data finally results in 9688 audio records with complete xml files associated to them.Download link of training data will be sent to participants on 05/02/2014.
The test data results in 4339 audio records with purged xml files.
Run format
The run file must be named as "teamname_runX.run" where X is the identifier of the run (i.e. 1, 2, 3 or 4). The run file has to contain as much lines as the total number of predictions, with at least one prediction and a maximum of 501 predictions per test audio record (501 being the total number of species). Each prediction item (i.e. each line of the file) has to respect the following format:
< MediaId;ClassId;rank;probability>
Here is a short fake run example respecting this format on only 8 test MediaId:
myTeam_run2.txt
For each submitted run, please give in the submission system a description of the run. A combobox will specify wether the run was performed fully automatically or with a human assistance in the processing of the queries. Then, a textarea should contain a short description of the used method, for helping differentiating the different runs submitted by the same group, and where we ask to the participants to indicate if they used a method based on
- only AUDIO
- only METADATA
- both AUDIO x METADA
For instance:
Only AUDIO, using provided MFFC features, multiple multi-class Support Vector Machines with probabilistic outputs
Optionally, you can add one or several bibtex reference(s) to publication(s) describing the method more in details.
Metric
The used metric is the mean Average Precision (mAP), considering each audio file of the test set as a query and computed as:
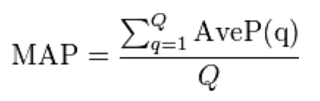
where Q is the number of test audio files and AveP(q) for a given test file q is computed as:
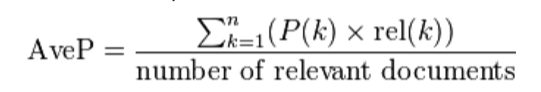
where k is the rank in the sequence of returned species, n is the total number of returned species, P(k) is the precision at cut-off k in the list and rel(k) is an indicator function equaling 1 if the item at rank k is a relevant species (i.e. one of the species in the ground truth).
How to register for the task
LifeCLEF will use the ImageCLEF registration interface. Here you can choose a user name and a password. This registration interface is for example used for the submission of runs. If you already have a login from the former ImageCLEF benchmarks you can migrate it to LifeCLEF 2014 here
Schedule
- 01.12.2013: Registration opens (register here)
- 05.02.2014: training data release
- 15.04.2014: test data release
08.05.201415.05.2014: deadline for submission of runs15.05.201422.05.2014:release of results- 07.06.2014: deadline for submission of working notes
- 09.2014: CLEF 2014 Conference (Sheffield, UK)
Frequently Asked Questions
Quality tag in XML
It ranges from 1-5, with 1 being best quality and 5 being worst quality, correct? 0 means unknown rating.
Yes.
What is the maximum allowed number of submissions?
The number of submissions is 4.
How is the classID field created? Can we relate genus and species information with class ID?
There is no obvious rule for relating the genus and species information in the class ID.
Run format : What is the rank field in the submission format?
The
Does every participant have to submit working notes for the conference?
We warmly encourage participants to submit working notes in order to make more credible the results obtained within the bioacoustic community.
Results
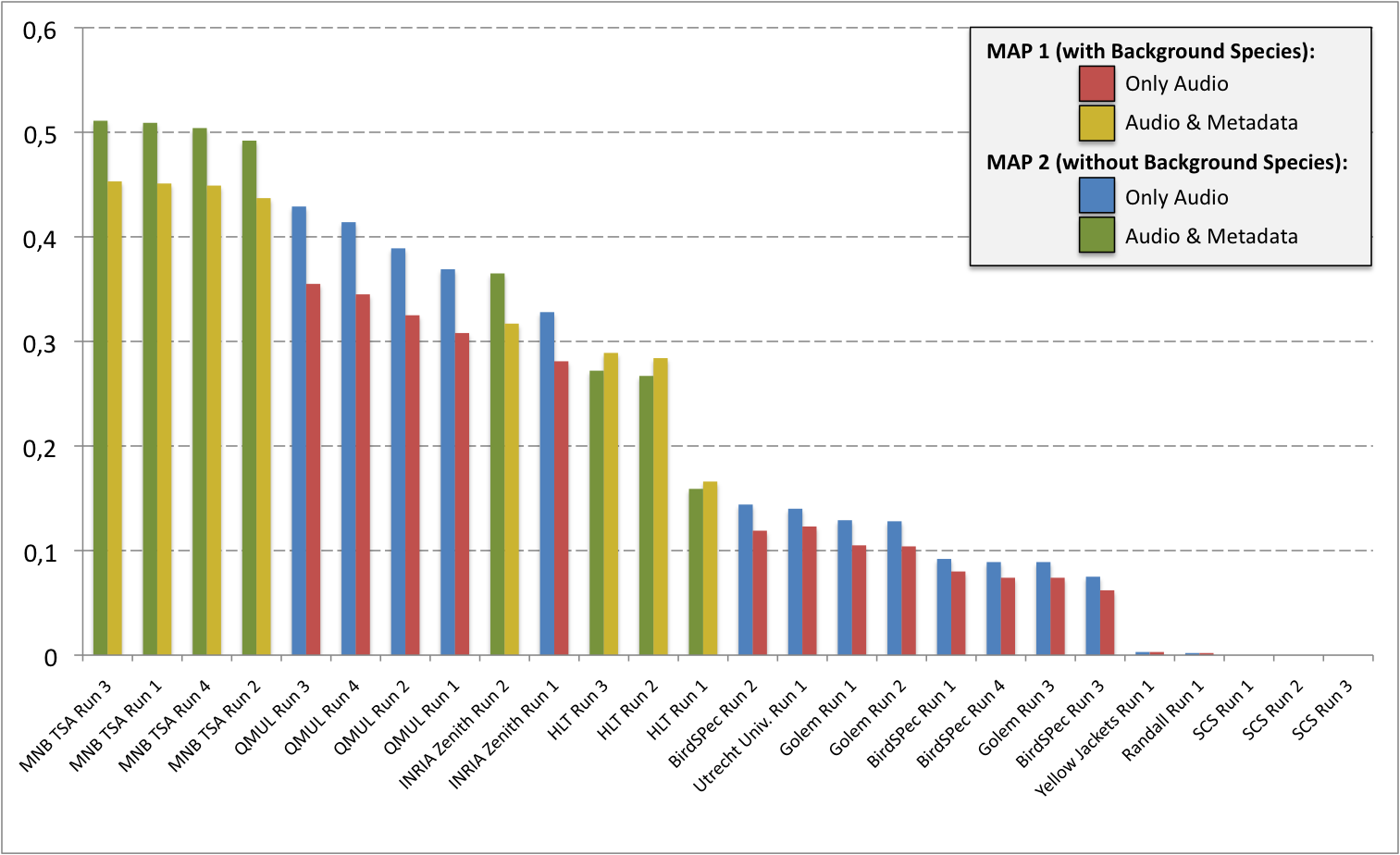
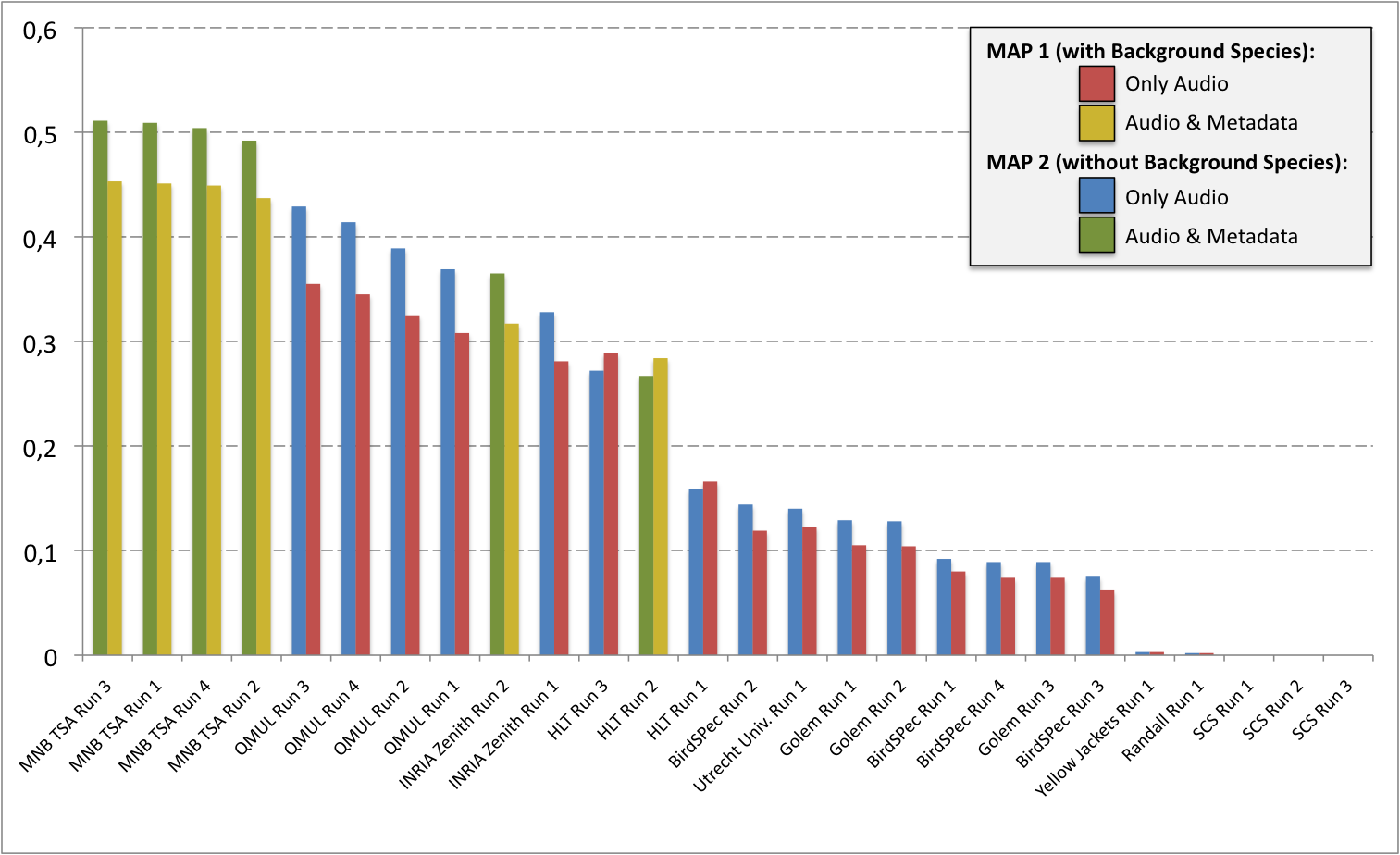
A total of 10 participating groups submitted 29 runs. Thanks to all of you for your efforts and your constructive feedbacks regarding the organization.
| Run name | Run filename | Type | MAP 1 (with Background Species) | MAP 2 (without Background Species) |
|---|---|---|---|---|
| MNB TSA Run 3 | 1400191117781__MarioTsaBerlin_run3 | AUDIO & METADATA | 0,453 | 0,511 |
| MNB TSA Run 1 | 1400189639693__MarioTsaBerlin_run1 | AUDIO & METADATA | 0,451 | 0,509 |
| MNB TSA Run 4 | 1400187879882__MarioTsaBerlin_run4 | AUDIO & METADATA | 0,449 | 0,504 |
| MNB TSA Run 2 | 1400155761267__MarioTsaBerlin_run2 | AUDIO & METADATA | 0,437 | 0,492 |
| QMUL Run 3 | 1398844676710__danstowell_run3 | AUDIO | 0,355 | 0,429 |
| QMUL Run 4 | 1399057195244__danstowell_run4 | AUDIO | 0,345 | 0,414 |
| QMUL Run 2 | 1398353349310__danstowell_run2 | AUDIO | 0,325 | 0,389 |
| QMUL Run 1 | 1398351214959__danstowell_run1 | AUDIO | 0,308 | 0,369 |
| INRIA Zenith Run 2 | 1398872637337__Run2-INRIA-Julien-Alexis-withMetadata | AUDIO & METADATA | 0,317 | 0,365 |
| INRIA Zenith Run 1 | 1398427280302__Run1-INRIA-Julien-Alexis | AUDIO | 0,281 | 0,328 |
| HLT Run 3 | 1399880572021__combined | AUDIO & METADATA | 0,289 | 0,272 |
| HLT Run 2 | 1399880101403__run10 | AUDIO & METADATA | 0,284 | 0,267 |
| HLT Run 1 | 1399429313760__jonfull | AUDIO & METADATA | 0,166 | 0,159 |
| BirdSPec Run 2 | 1400164626383__BiRdSPec_run2 | AUDIO | 0,119 | 0,144 |
| Utrecht Univ. Run 1 | 1400099635524__clef_240350350v | AUDIO | 0,123 | 0,14 |
| Golem Run 1 | 1400173600537__golem_run1 | AUDIO | 0,105 | 0,129 |
| Golem Run 2 | 1400200584201__golem_run2 | AUDIO | 0,104 | 0,128 |
| BirdSPec Run 1 | 1400163565260__BiRdSPec_run1 | AUDIO | 0,08 | 0,092 |
| BirdSPec Run 4 | 1400189292631__BiRdSPec_run4 | AUDIO | 0,074 | 0,089 |
| Golem Run 3 | 1400200893582__golem_run3 | AUDIO | 0,074 | 0,089 |
| BirdSPec Run 3 | 1400165270133__BiRdSPec_run3 | AUDIO | 0,062 | 0,075 |
| Yellow Jackets Run 1 | 1399489750608__Aneesh_run_1 | AUDIO | 0,003 | 0,003 |
| Randall Run 1 | 1400270035158__RandallDylan_run1 | AUDIO | 0,002 | 0,002 |
| SCS Run 1 | 1398890068906__scs_run1 | AUDIO | 0 | 0 |
| SCS Run 2 | 1399201734708__scs_run2 | AUDIO | 0 | 0 |
| SCS Run 3 | 1399834505835__scs_run3 | AUDIO | 0 | 0 |
| Perfect Main Species | perfectRunMainLabel | AUDIO | 0,784 | 1 |
| Perfect Main & Bacground Species | perfectRunMultiLabel | AUDIO | 1 | 0,868 |
| Random Main Species | randomRunMonoLabel | AUDIO | 0,003 | 0,003 |
____________________________________________________________________________________________________________________
Contacts
Main contact: lifeclef@inria.fr
| Attachment | Size |
|---|---|
| 1.65 MB | |
| 573.56 KB | |
| 1.1 KB | |
| 123.97 KB | |
| 123.93 KB |
{kind=link}
{kind=link}
{kind=link}
{kind=link}