- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
ToPicto
 Welcome to the 1st edition of the ToPicto task!
Welcome to the 1st edition of the ToPicto task!
Motivation
Several genetic diseases, such as Rett syndrome, can result in language impairment, thereby interfering with the development of language skills such as speaking, listening, reading, and writing. Both language production and comprehension are impaired. Language impairment may also arise from incidents such as a car accident or a stroke, leading to aphasia — a partial or complete loss of the ability to express oneself or understand written and spoken language. In these particular cases, Augmentative and Alternative Communication (AAC) can be implemented. AAC involves the use of pictograms to help individuals accurately convey their messages [1].
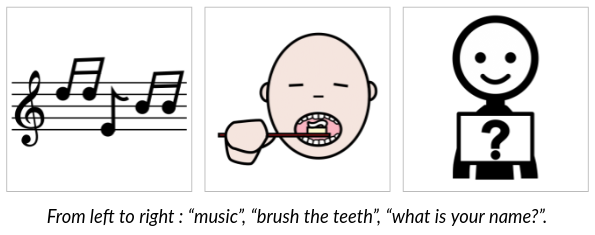 In AAC, Pictograms refer to an image representing a more or less concrete concept. It can be a single word, a named entity, or a polylexical expression among others (see the example with pictograms taken from ARASAAC, a collection featuring over 25,000 pictograms freely available under a Creative Commons CC-BY-NC-SA license).
In AAC, Pictograms refer to an image representing a more or less concrete concept. It can be a single word, a named entity, or a polylexical expression among others (see the example with pictograms taken from ARASAAC, a collection featuring over 25,000 pictograms freely available under a Creative Commons CC-BY-NC-SA license).
Using pictograms as a communication aid has proven effective in visualizing syntax, manipulating words, and facilitating language access [2]. Moreover, the use of AAC has a positive social impact for individuals with language impairment. The “Croix-Rouge” (French Red Cross) has identified a reduction in stress, an improvement in autonomy and health, and greater serenity and enjoyment in daily life [3]. However, not everyone has prior knowledge about AAC and pictograms. Yet, in a situation where a “verbal” person aims to communicate with an AAC user, a tool that converts the two modalities — speech and text — into a sequence of pictograms is essential. By providing a relevant and comprehensible sequence of pictograms for the impaired person, the communication between the two parties can be initiated.
The goal of ToPicto is to bring together linguists, computer scientists, and translators to develop new translation methods to translate either speech or text into a corresponding sequence of pictograms.
News
- 21.12.2023: Website goes live and registration is open.
Tasks Description
The participants will be requested to develop solutions for translating text or speech into a sequence of pictogram terms, with each of them linked to a unique pictogram image from ARASAAC.
ImageCLEFToPicto 2024 consists of two substaks:
- Text-to-Picto
- Speech-to-Picto
Text-to-Picto

Text-to-Picto task focuses on the automatic generation of a corresponding sequence of pictogram terms from a French text. This challenge can be seen as a translation problem, where the source language is French, and the target language is French pictogram terms.
The providing translation has to follow the specifications regarding a translation in pictograms, understandable by AAC users.
Speech-to-Picto

Speech-to-Picto focuses on the two modalities speech and pictograms. The challenge is to directly translate speech to pictogram terms without going through the transcription dimension, which is the focus of the speech community with current spoken language translation systems.
Data
The data for the two tasks is built from the TCOF corpus (https://tcof.atilf.fr/) [4]. TCOF contains interactions between adults, adults and children, and children themselves, covering a wide range of topics including debates, everyday situations, and medical consultations. This type of text is representative of the interactions we observe between caregivers (families, medical staff) and individuals who rely on pictograms due to language impairments.
For ToPicto, we provide a corresponding sequence of terms linked to a pictogram from either the speech utterance or the oral transcription.
Below is detailed information about each input and the expected output format for each task.
Text-to-Picto
Input : a json file with the following information (only for training and validation data, for test you will be only given the id and src):
| Tag | Definition | Example | |
|---|---|---|---|
| id | unique identifier of each utterance | cefc-tcof-Acc_del_07-1 | |
| src | source of the utterance - text from oral transcription | tu peux pas savoir | |
| tgt | target of the utterance - sequence of pictogram terms (tokens) | toi pouvoir savoir non | |
| pictos | a list of pictogram identifiers linked to each pictogram terms (the size is the same as the target output).* | [6625, 35949, 16885, 5526] | |
 |
* This information is provided for reference to give an idea of the input with the sequence of pictogram images. Each image can be obtained from the ARASAAC website as follows: https://api.arasaac.org/v1/pictograms/6625
Output: a json file with the following information:
| Tag | Definition | Example |
|---|---|---|
| id | unique identifier of each utterance | cefc-tcof-Acc_del_07-1 |
| hyp | hypothesis given by your system / model corresponding to the sequence of pictogram terms | toi savoir non |
Speech-to-Picto
The input and output are the same, with the only distinction being that in the input, the source is the audio file linked to the ID in .wav format: cefc-tcof-Acc_del_07-1.wav.
Evaluation methodology
The evaluation is conducted using BLEU [5], METEOR [6], and the Picto-term Error Rate (PictoER) [7]. For all three metrics, the evaluation involves comparing the hypothesis (hyp) with the target (tgt), i.e., the sequence of pictogram terms.
Scripts provided: We provide a script that maps the pictogram terms to the pictogram images to visualize the output sequence.
Participant registration
The registration is open here:
- Text-to-Picto - https://ai4media-bench.aimultimedialab.ro/competitions/18/
- Speech-to-Picto - https://ai4media-bench.aimultimedialab.ro/competitions/19/
For general information, please refer to ImageCLEF registration instructions.
Important Dates
17.01.2024NEW DATE: 09.02.2024: Training and validation data release.- 14.03.2024: Test data release.
More information will be added soon!
Submission instructions
More information will be added soon!
Results
More information will be added soon!
Contact
Organizers:
- Cécile Macaire — <cecile.macaire(at)univ-grenoble-alpes.fr>, Université Grenoble Alpes, LIG, France
- Benjamin Lecouteux — <benjamin.lecouteux(at)univ-grenoble-alpes.fr>, Université Grenoble Alpes, LIG, France
- Didier Schwab — <didier.schwab(at)univ-grenoble-alpes.fr>, Université Grenoble Alpes, LIG, France
- Emmanuelle Esperança-Rodier — <emmanuelle.esperanca-rodier(at)univ-grenoble-alpes.fr>, Université Grenoble Alpes, LIG, France
Acknowledgments
ToPicto is organized as part of the PROPICTO project, and supported by the following partners:
![]()
References
[1] Romski, M., & Sevcik, R. A. (2005). Augmentative communication and early intervention: Myths and realities. Infants & Young Chitdren, 18(3), 174-185.
[2] Cataix-Nègre, É. (2017). Communiquer autrement: Accompagner les personnes avec des troubles de la parole ou du langage : les communications alternatives. De Boeck Supérieur.
[3] Communication alternative améliorée (CAA) : la Croix-Rouge française dévoile sa première étude d’impact social ! (2021, April 12). Croix-Rouge. Retrieved June 28, 2023, from https://www.croix-rouge.fr/actualite/communication-alternative-amelioree...
[4] André, V., & Canut, E. (2010). Mise à disposition de corpus oraux interactifs : le projet TCOF (Traitement de Corpus Oraux en Français). Pratiques. Linguistique, littérature, didactique, (147-148), 35-51.
[5] Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002, July). Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics (pp. 311-318).
[6] Banerjee, S., & Lavie, A. (2005, June). METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization (pp. 65-72).
[7] Woodard, J. P., & Nelson, J. T. (1982, March). An information theoretic measure of speech recognition performance. In Workshop on standardisation for speech I/O technology, Naval Air Development Center, Warminster, PA.