- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
BirdCLEF 2018

Usage scenario
As in 2017, two scenarios will be evaluated, (i) the identification of a particular bird specimen in a recording of it, and (ii), the recognition of all specimens singing in a long sequence (up to one hour) of raw soundscapes that can contain tens of birds singing simultaneously. The first scenario is aimed at developing new interactive identification tools, to help user and expert who is today equipped with a directional microphone and spend too much time observing and listening the birds to assess their population on the field. The soundscapes, on the other side, correspond to a passive monitoring scenario in which any multi-directional audio recording device could be used without or with very light user’s involvement, and thus efficient biodiversity assessment.
Subtask1: monophone recordings
Task overview
The goal of the task is to identify the species of the most audible bird (i.e. the one that was intended to be recorded) in each of the provided test recordings. Therefore, the evaluated systems have to return a ranked list of possible species for each of the 12,347 test recordings. Each prediction item (i.e. each line of the file to be submitted) has to respect the following format:
< MediaId;ClassId;Probability;Rank>
Each participating group is allowed to submit up to 4 runs built from different methods. Semi-supervised, interactive or crowdsourced approaches are allowed but will be compared independently from fully automatic methods. Any human assistance in the processing of the test queries has therefore to be signaled in the submitted runs.
Participants are allowed to use any of the provided metadata complementary to the audio content (.wav 44.1, 48 kHz or 96 kHz sampling rate), and will also be allowed to use any external training data but at the condition that (i) the experiment is entirely re-producible, i.e. that the used external resource is clearly referenced and accessible to any other research group in the world, (ii) participants submit at least one run without external training data so that we can study the contribution of such resources, (iii) the additional resource does not contain any of the test observations. It is in particular strictly forbidden to crawl training data from: www.xeno-canto.org
Dataset
The data collection will be the same as the one used in BirdCLEF 2017, mostly based on the contributions of the Xeno-Canto network. The training set contains 36,496 recordings covering 1500 species of central and south America (the largest bioacoustic dataset in the literature). It has a massive class imbalance with a minimum of four recordings for Laniocera rufescens and a maximum of 160 recordings for Henicorhina leucophrys. Recordings are associated to various metadata such as the type of sound (call, song, alarm, flight, etc.), the date, the location, textual comments of the authors, multilingual common names and collaborative quality ratings. The test set contains 12,347 recordings of the same type (mono-phone recordings). More details about that data can be found in the overview working note of BirdCLEF 2017.
Metric
The used metric will be the Mean Reciprocal Rank (MRR). The MRR is a statistic measure for evaluating any process that produces a list of possible responses to a sample of queries ordered by probability of correctness. The reciprocal rank of a query response is the multiplicative inverse of the rank of the first correct answer. The MRR is the average of the reciprocal ranks for the whole test set:
where |Q| is the total number of query occurrences in the test set.

Mean Average Precision will be used as a secondary metric to take into account the background species, considering each audio file of the test set as a query and computed as:
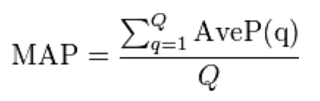
where Q is the number of test audio files and AveP(q) for a given test file q is computed as:
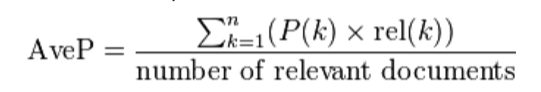
where k is the rank in the sequence of returned species, n is the total number of returned species, P(k) is the precision at cut-off k in the list and rel(k) is an indicator function equaling 1 if the item at rank k is a relevant species (i.e. one of the species in the ground truth).
Subtask2: soundscape recordings
Task overview
The goal of the task is to localize and identify all audible birds within the provided soundscape recordings. Each soundscape will have to be divided into segments of 5 seconds, and a list of species associated to probability scores will have to be returned for each segment. Each prediction item (i.e. each line of the file) has to respect the following format:
< MediaId;TC1-TC2;ClassId;Probability>
where probability is a real value in [0;1] decreasing with the confidence in the prediction, and where TC1-TC2 is a timecode interval with the format of hh:mm:ss with a length of 5 seconds (e.g.: 00:00:00-00:00:05, then 00:00:05-00:00:10).
Each participating group is allowed to submit up to 4 runs built from different methods. Semi-supervised, interactive or crowdsourced approaches are allowed but will be compared independently from fully automatic methods. Any human assistance in the processing of the test queries has therefore to be signaled in the submitted runs.
Participants are allowed to use any of the provided metadata complementary to the audio content (.wav 44.1, 48 kHz or 96 kHz sampling rate), and will also be allowed to use any external training data but at the condition that (i) the experiment is entirely re-producible, i.e. that the used external resource is clearly referenced and accessible to any other research group in the world, (ii) participants submit at least one run without external training data so that we can study the contribution of such resources, (iii) the additional resource does not contain any of the test observations. It is in particular strictly forbidden to crawl training data from: www.xeno-canto.org
Dataset
The training set contains 36,496 monophone recordings of the Xeno-Canto network covering 1500 species of central and south America (the largest bioacoustic dataset in the literature). It has a massive class imbalance with a minimum of four recordings for Laniocera rufescens and a maximum of 160 recordings for Henicorhina leucophrys. Recordings are associated to various metadata such as the type of sound (call, song, alarm, flight, etc.), the date, the location, textual comments of the authors, multilingual common names and collaborative quality ratings.
Complementary to that data, a validation set of soundscapes with time-coded labels will be provided as training data. It contains about 20 minutes of soundscapes representing 240 segments of 5 seconds and with a total of 385 bird species annotations.
The test set itself will contain about 6 hours of soundscapes split in 4382 segments of 5 seconds (to be processed as separate queries). Some of them will be Stereophonic, offering possible sources separation to enhance the recognition.
Metric
The used metric will be the classification mean Average Precision (c-mAP), considering each class c of the ground truth as a query. This means that for each class c, we will extract from the run file all predictions with ClassId=c, rank them by decreasing probability and compute the average precision for that class. We will then take the mean across all classes. More formally:
![]()
where C is the number of species in the ground truth and AveP(c) is the average precision for a given species c computed as:
![]()
where k is the rank of an item in the list of the predicted segments containing c, n is the total number of predicted segments containing c, P(k) is the precision at cut-off k in the list, rel(k) is an indicator function equaling 1 if the segment at rank k is a relevant one (i.e. is labeled as containing c in the ground truth) and nrel is the total number of relevant segments for c.
Results
A total of 6 participating groups submitted a total of 45 runs (23 runs for the "Subtask1: monophone recordings" and 22 runs for the "Subtask2: soundscape recordings"). Thanks to all of you for your efforts and your constructive feedbacks regarding the organization!
The following figure and table and give the results for the Subtask1 (monophone recordings):
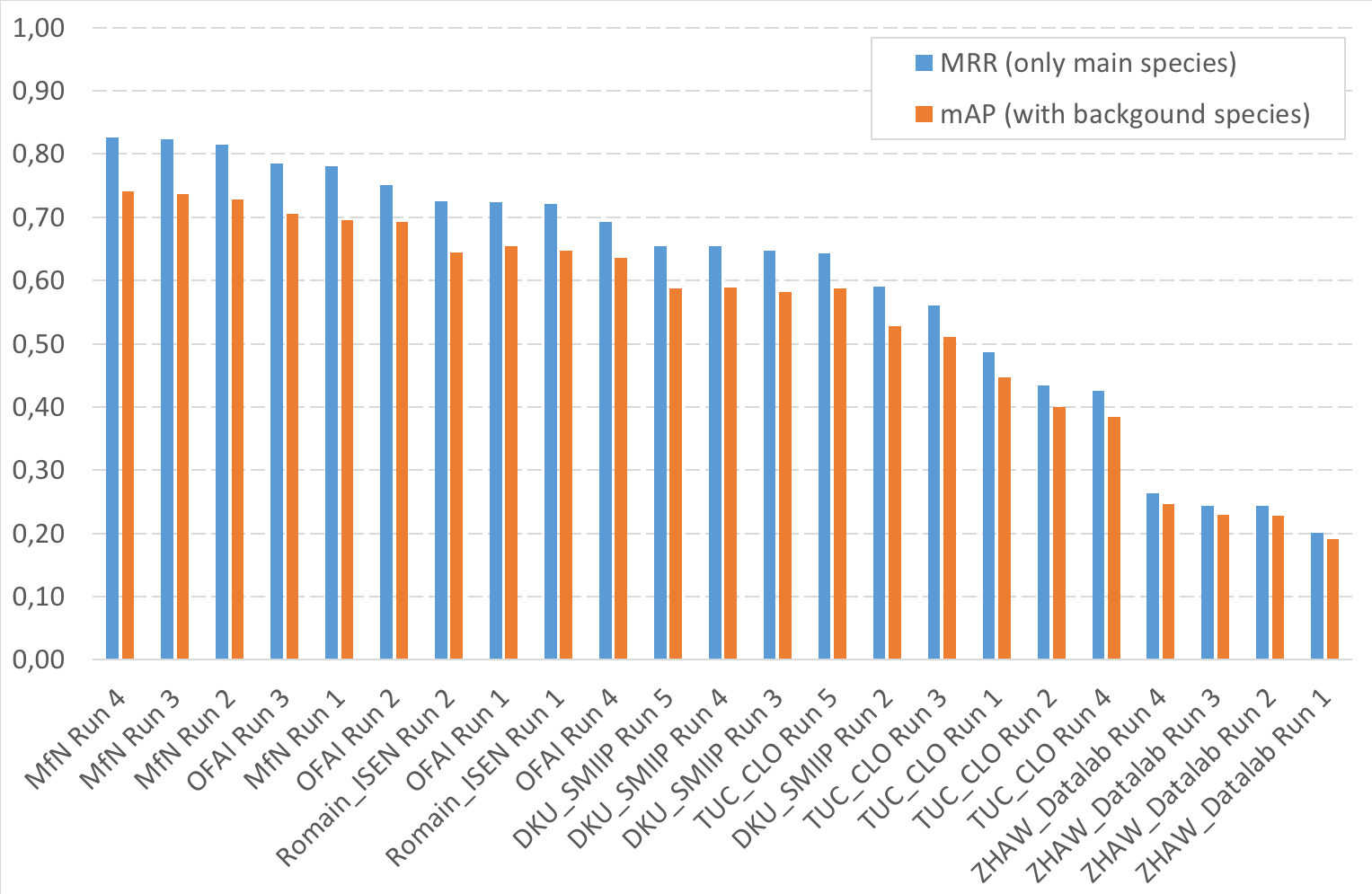
| Team run | filename | MRR (only main species) | mAP (with backgound species) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MfN Run 4 | a0d4abd6-729c-4374-9d1b-a698c741e0b3_LifeClef2018BirdMonophoneMfN04.csv | 0,8266 | 0,7404
| MfN Run 3 |
805a062b-c9b3-46a0-bcf5-788dc5acfe1b_LifeClef2018BirdMonophoneMfN03.csv |
0,8235 |
0,7374
| MfN Run 2 |
b576ab51-4f10-4591-a262-4ecada75ee9f_LifeClef2018BirdMonophoneMfN02.csv |
0,8147 |
0,7280
| OFAI Run 3 |
47f78f5c-3986-4bac-b1ad-fe8b09a8ab81_run3.csv |
0,7849 |
0,7049
| MfN Run 1 |
a769a8ba-f4ee-4260-887f-88bf36e82805_MfN01.csv |
0,7803 |
0,6956
| OFAI Run 2 |
2972ae1d-9f68-4402-a28b-4ad9768d89ac_run2.csv |
0,7516 |
0,6921
| Romain_ISEN Run 2 |
a9e60035-c6fb-4379-8246-7b70d45c7b53_rads_run1.txt |
0,7251 |
0,6450
| OFAI Run 1 |
e7112055-1285-4568-8002-b857888ceb8d_run1.csv |
0,7240 |
0,6545
| Romain_ISEN Run 1 |
dc6d12a0-fc40-49c9-90b3-1ad260f482b4_rads_run2.txt |
0,7209 |
0,6478
| OFAI Run 4 |
62c02318-7ed0-427d-a0d7-f718160108ed_run4.csv |
0,6929 |
0,6363
| DKU_SMIIP Run 5 |
4f88a4c8-703c-4e99-9dbf-843aced6a92b_mono_fused_dku.csv |
0,6548 |
0,5882
| DKU_SMIIP Run 4 |
74b92982-4152-42e1-8b84-8f49b419cdcf_run4_mono.csv |
0,6541 |
0,5883
| DKU_SMIIP Run 3 |
19ef59c9-0906-4a57-b543-5d3168cfbe3f_final_fuse.csv |
0,6476 |
0,5814
| TUC_CLO Run 5 |
f14fe167-ede5-4fcc-86c9-b3b72b45ed05_BirdCLEF_TUC_CLO_ResNet_LARGE_ENSEMBLE_MONOPHONE_SUBMISSION_5.txt |
0,6435 |
0,5879
| DKU_SMIIP Run 2 |
27870af1-e39a-4189-9d40-3ff59b7c88a3_mono_aug.txt |
0,5896 |
0,5278
| TUC_CLO Run 3 |
99678ac2-acb4-4a43-8f7f-f2cf7ccea64c_BirdCLEF_TUC_CLO_ResNet_ENSEMBLE_MONOPHONE_SUBMISSION_3.txt |
0,5602 |
0,5114
| TUC_CLO Run 1 |
235603b5-aa20-4115-ae95-08459b678a41_BirdCLEF_TUC_CLO_Baseline_SINGLE BEST_MONOPHONE_SUBMISSION_1.txt |
0,4872 |
0,4475
| TUC_CLO Run 2 |
a63c35d2-8a56-4ff2-b602-11cd4a2ee8fd_BirdCLEF_TUC_CLO_ResNet_SINGLE_BEST_MONOPHONE_SUBMISSION_2.txt |
0,4347 |
0,3996
| TUC_CLO Run 4 |
5da39e73-28b4-41a3-82b9-9d86174fa47c_BirdCLEF_TUC_CLO_PiNet_SINGLE_BEST_MONOPHONE_SUBMISSION_4.txt |
0,4248 |
0,3846
| ZHAW_Datalab Run 4 |
133a7215-7a15-433d-94be-a8f95f295590_zhaw_run4_mono.csv |
0,2642 |
0,2466
| ZHAW_Datalab Run 3 |
d19c6d20-5f1a-446b-b921-c0c24a80d76f_zhaw_run3_mono.csv |
0,2441 |
0,2295
| ZHAW_Datalab Run 2 |
d38c9aef-588c-48e8-9fae-794f93a9cbb7_zhaw_run2_mono.csv |
0,2439 |
0,2285
| ZHAW_Datalab Run 1 |
741d903d-1700-495c-9d1f-8468a26b0577_zhaw_run1_mono.csv |
0,2014 |
0,1909
| |
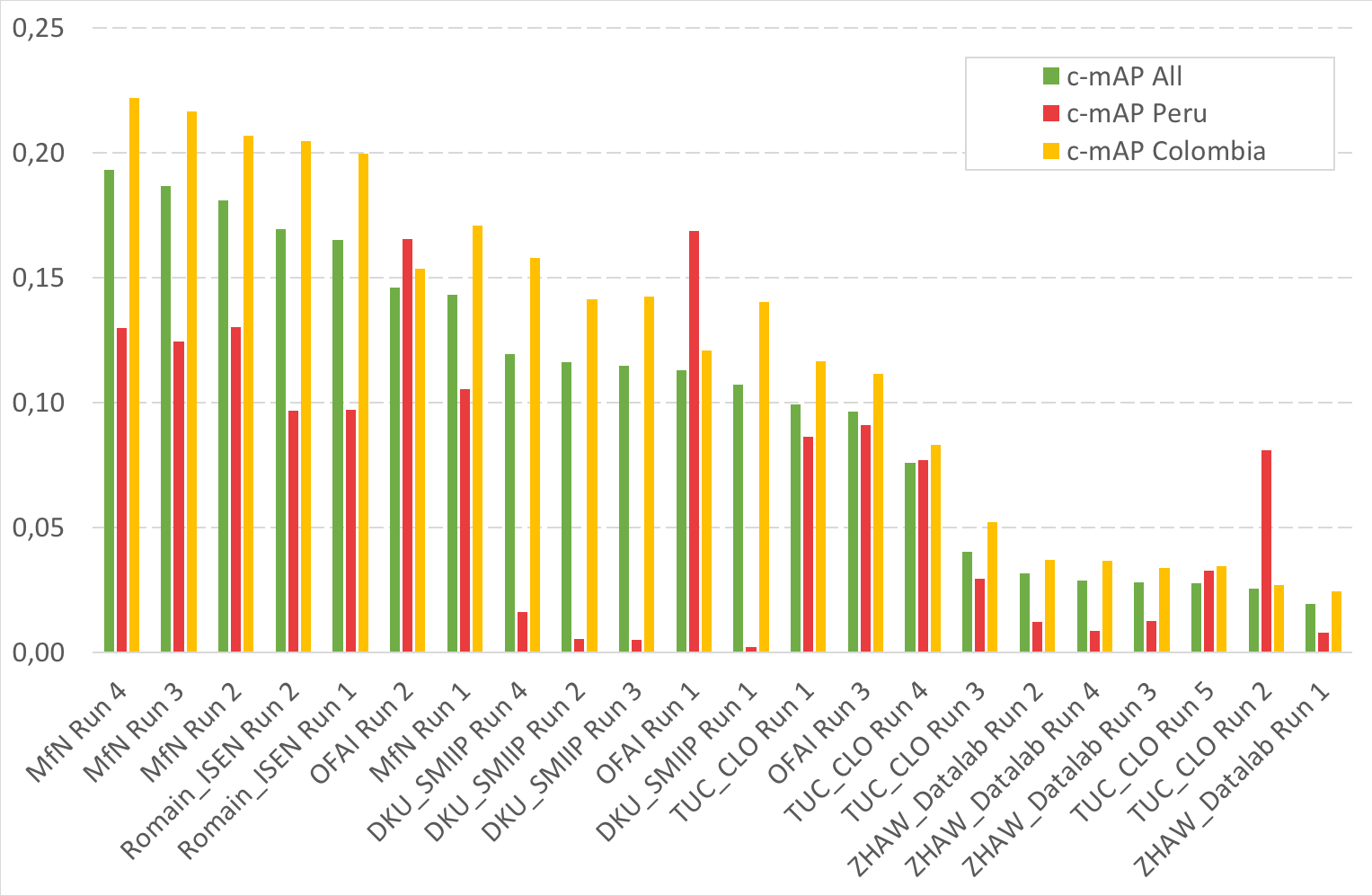
The following figure and table and give the results for the Subtask2 (soundscape recordings). A third figure gives detailed results by country.
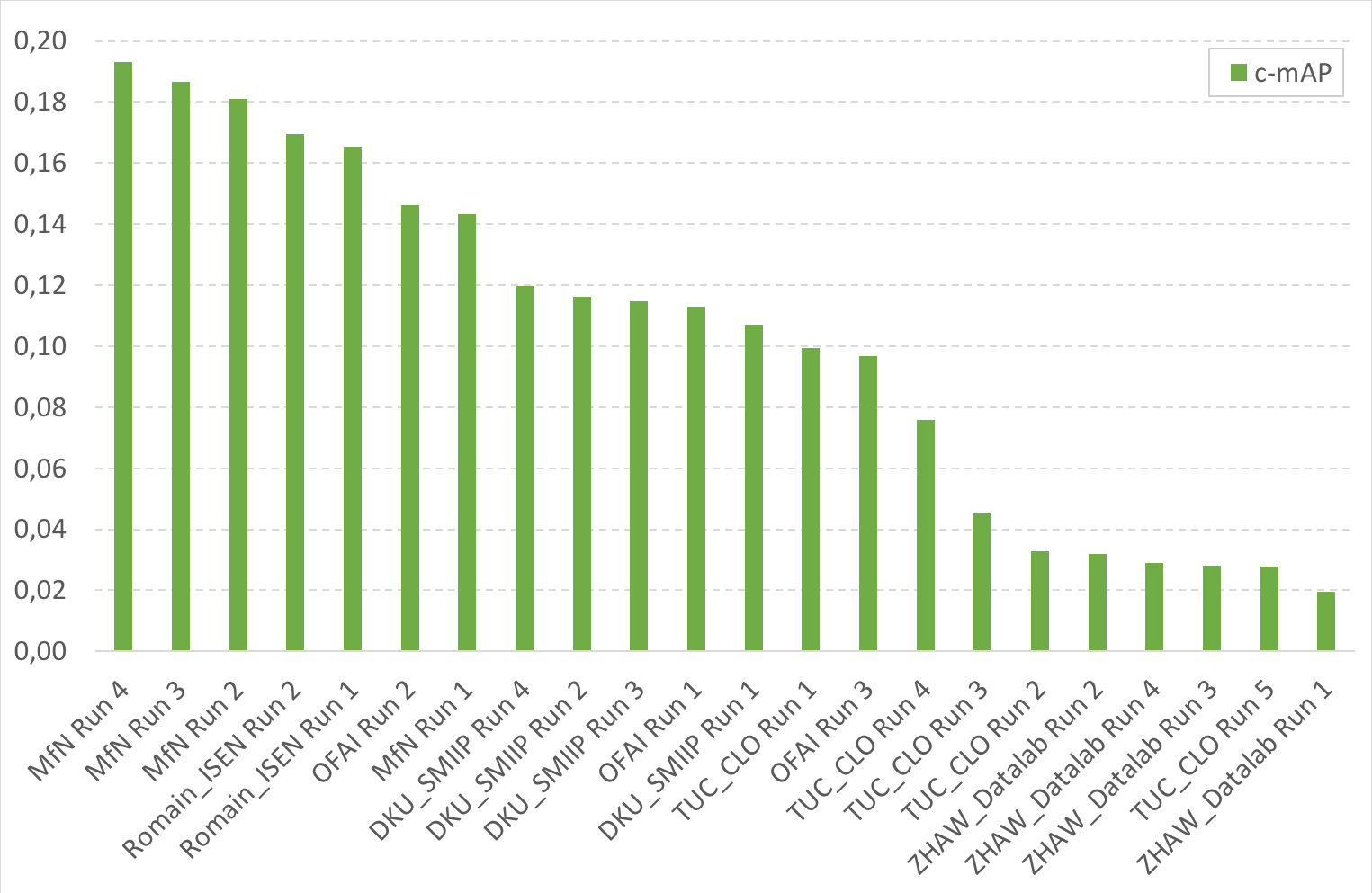
| Team run | filename | c-mAP | c-mAP Peru | c-mAP Colombia | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MfN Run 4 | dc26c029-4bfc-40c0-ac0f-43f31d8c57ca_LifeClef2018BirdSoundscapeMfN04.csv | 0,1931 | 0,1299 | 0,2220
| MfN Run 3 |
57b6450c-9bd5-4bf2-9313-edcaf5c8a198_LifeClef2018BirdMonophoneMfN03.csv |
0,1866 |
0,1244 |
0,2164
| MfN Run 2 |
ac2b34bb-2615-439f-8c76-dba07ed906ba_LifeClef2018BirdSoundscapeMfN02.csv |
0,1809 |
0,1303 |
0,2069
| Romain_ISEN Run 2 |
65c99c01-7c35-4173-b8ec-2e2979faa2e5_rads_run2.txt |
0,1695 |
0,0967 |
0,2048
| Romain_ISEN Run 1 |
a830205e-ee42-4d16-9fb1-b90ccbc7e4d1_rads_run1.txt |
0,1652 |
0,0973 |
0,1994
| OFAI Run 2 |
d3f75ddf-84d1-456a-a2ac-c71dded050cd_run2.csv |
0,1461 |
0,1655 |
0,1536
| MfN Run 1 |
8c2f97ca-f4d3-4416-9642-dbf2142af255_LifeClef2018BirdSoundscapeMfN01.csv |
0,1432 |
0,1055 |
0,1710
| DKU_SMIIP Run 4 |
ed540efe-21ee-430c-b5fc-28c76899d3f6_soundscape_fused_4.csv |
0,1196 |
0,0163 |
0,1578
| DKU_SMIIP Run 2 |
69c725b6-c9a3-4ae1-a6c7-d4bb06bff743_soundscape_fuse_3.csv |
0,1161 |
0,0055 |
0,1415
| DKU_SMIIP Run 3 |
2c8119fa-d915-48a0-af5f-2bd4b6949078_soundscape_run4.csv |
0,1147 |
0,0053 |
0,1424
| OFAI Run 1 |
14af5cff-04b2-45c5-b4aa-1384ad59417f_run1.csv |
0,1130 |
0,1687 |
0,1210
| DKU_SMIIP Run 1 |
39b5c0c3-633c-489b-9f70-a41b6bd520f1_soundscape_aug_re_his_nometa.txt |
0,1071 |
0,0024 |
0,1403
| TUC_CLO Run 1 |
8570dff8-1dc8-4194-b119-86027fa666fc_BirdCLEF_TUC_CLO_ResNet_ENSEMBLE_SOUNDSCAPE_SUBMISSION_1.txt |
0,0995 |
0,0864 |
0,1167
| OFAI Run 3 |
a03f83c9-d324-4829-b5c2-e539e3fbf862_run4.csv |
0,0966 |
0,0911 |
0,1116
| TUC_CLO Run 4 |
49a8b281-0860-43db-a2c7-4b91b86dde35_BirdCLEF_TUC_CLO_PiNet_SINGLE_BEST_SOUNDSCAPE_SUBMISSION_4.txt |
0,0758 |
0,0772 |
0,0830
| TUC_CLO Run 3 |
4119c89d-4d0b-4fe0-bae5-aaa9b1e24813_BirdCLEF_TUC_CLO_ResNet_COLOMBIA_SOUNDSCAPE_SUBMISSION_3.txt |
0,0406 |
0,0296 |
0,0522
| ZHAW_Datalab Run 2 |
efbd59f4-70ce-47bd-8160-ecea964d15b1_zhaw_run2_soundscape.csv |
0,0319 |
0,0123 |
0,0370
| ZHAW_Datalab Run 4 |
baed19f2-47c1-41b0-a21a-0e8ff6d74670_zhaw_run4_soundscapes.csv |
0,0291 |
0,0090 |
0,0370
| ZHAW_Datalab Run 3 |
1df5d381-4f09-47cb-80b5-1bdab32c3360_zhaw_run3_soundscapes.csv |
0,0281 |
0,0126 |
0,0339
| TUC_CLO Run 5 |
d414ad30-7b24-4253-a739-e7511d3ae867_BirdCLEF_TUC_CLO_ResNet_LARGE_ENSEMBLE_SOUNDSCAPE_SUBMISSION_5.txt |
0,0277 |
0,0330 |
0,0346
| TUC_CLO Run 2 |
ac953b8c-77f0-4322-8a82-5dc2321677cd_BirdCLEF_TUC_CLO_ResNet_PERU_SOUNDSCAPE_SUBMISSION_2.txt |
0,0258 |
0,0809 |
0,0272
| ZHAW_Datalab Run 1 |
1010a3d6-dbab-4083-9f0a-38885c4f8feb_zhaw_run1_soundscape.csv |
0,0195 |
0,0079 |
0,0244
| |
| Attachment | Size |
|---|---|
| 140.8 KB | |
| 141.42 KB | |
| 158.9 KB | |
| 158.05 KB |
{kind=link}
{kind=link}
{kind=link}
{kind=link}