- ImageCLEF 2026
- LifeCLEF 2026
- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
Fish task

News
Results have been released on June, 1st 2014.
Context
Underwater video monitoring has been widely used in recent years for marine video surveillance, as opposed to human manned photography or net-casting methods, since it does not influence fish behavior and provides a large amount of material at the same time. However, it is impractical for humans to manually analyze the massive quantity of video data daily generated, because it requires much time and concentration and it is also error prone. An automatic fish identification system in videos is therefore of crucial importance, in order to estimate fish existence and quantity. Moreover, it would help supporting marine biologists to understand the natural underwater environment, promote its preservation, and study behaviors and interactions between marine animals that are part of it. Beyond this, video-based fish species identification finds applications in many other contexts: from education (e.g. primary/high schools) to the entertainment industry (e.g. in aquarium).
Task Description
The dataset for the video-based fish identification task will be released in two times: the participants will first have access to the training set and a few months later, they will be provided with the testing set. The goal is to automatically detect fish and its species. The task comprises three sub-tasks: 1) identifying moving objects in videos by either background modeling or object detection methods, 2) detecting fish instances in video frames and then 3) identifying species (taken from a subset of the most seen fish species) of fish detected in video frames and 4) identifying fish species using only still images containing only one fish instance.
Dataset
The underwater video dataset will be derived from the Fish4Knowledge (www.fish4knowledge.eu) video repository, which contains about 700k 10-minute video clips that were taken in the past five years to monitor Taiwan coral reefs. The Taiwan area is particularly interesting for studying the marine ecosystem, as it holds one of the largest fish biodiversities of the world with more than 3000 different fish species whose taxonomy is available at http://fishdb.sinica.edu.tw/. The dataset contains videos recorded from sunrise to sunset showing several phenomena, e.g. murky water, algae on camera lens, etc., which makes the fish identification task more complex. Each video has a resolution of either 320x240 or 640x480 with 5 to 8 fps and comes with some additional metadata including date and localization of the recordings.
More specifically, the dataset consists of more than 1000 videos with several thousands of detected fish. Only for a small portion (about 20K) of the detected fish, the species will be provided. In addition, only 10 fish species will be considered as they represent almost the totality of the fish observed by the Taiwanese coral reef.
Training Dataset
The FISHCLEF Training Dataset contains the datasets for all the aforementioned subtasks. In total, three folders are provided:
- Ground truth folder where the ground truths for the three subtasks are given as XML files:

- Videos folder where all the videos of the entire dataset are contained.
- Images folder which contains the images corresponding to the bounding boxes given in the XML file. These images are provided only for subtasks 2 and 3 as they are image-based tasks.
The training dataset is a zip file of about 40 GB ground truth file and is so composed:
- Subtask 1- Video Based Fish Identification: Four videos fully labeled, 21106 annotations corresponding to 9852 different fish instances.
- Subtask 2- Image Based Fish Identification: 957 videos labeled with 112078 fish annotated
- Subtask 3- Image Based Fish Identification and Species Recognition: 285 videos labeled with 19868 fish (and their species) annotated.
- Subtask 4- Image Based Fish Species Recognition: 19868 fish images annotated.
Test Dataset
The FISHCLEF Test Dataset contains the datasets for all the aforementioned subtasks. In total, three folders are provided:
- Tasks folder where the tasks' description and examples of the XML run file are given
- Videos folder where all the videos of the entire dataset are contained.
- Images folder which contains the fish images for subtask 4.
The test dataset is a zip file of about 8 GB ground truth file and is so composed:
- Subtask 1- Video Based Fish Identification: 4 videos;
- Subtask 2- Image Based Fish Identification: 89 videos
- Subtask 3- Image Based Fish Identification and Species Recognition: 116 videos;
- Subtask 4- Image Based Fish Species Recognition: 6956 fish images .
Run Format
The participants must provide a run file named as TeamName_SubTaskN_runX.XML where N is the number of the task (1 or 2 or 3) and X is the identifier of the run. The run file must have the same format as the ground truth xml file, i.e. it must contain the frame where the fish have been detected together with the bounding box (for all the three tasks), contours (only task 1) and species name (for task 3) of the fish.
Each subtask folder in the test dataset provides an example of run file in XML (e.g. http://f4k.nchc.org.tw/ucat/nas/fishclef_test_browse/tasks/subtask_4/exa... for subtask4).
Metrics
As scoring functions, the organisers will compute:
- For subtask 1: precision, recall and F-measures measured when comparing, on a pixel basis, the ground truth and the run outputs;
- For subtask 2: recall for fish detection in still images as a function of bounding box overlap percentage: a detection (in the run file) will be considered true positive if the PASCAL score between it and the corresponding object in the ground truth will be over 0.5;
- For subtask 3: Average precision and recall and precision and recall for each fish species;
- For subtask 4: Average recall and recall for each fish species.
Results
In total only two teams submitted runs for the fish task: one group for subtask 3 and one for subtask 4.
The baselines for the two tasks are:
- Subtask 3The ViBe background modeling approach for fish detection and VLFeat+BoW for fish species recognition
- Subtask 4 VLFeat+BoW for fish species recognition
The results achieved by the I3S team for subtask3 are here reported and compared to our baseline. When computing the performance in terms of fish detection, we relaxed the constrain on the PASCAL score as the I3S team often detected correctly a fish but the bouding box' size was much bigger than the one we provided in our dataset.
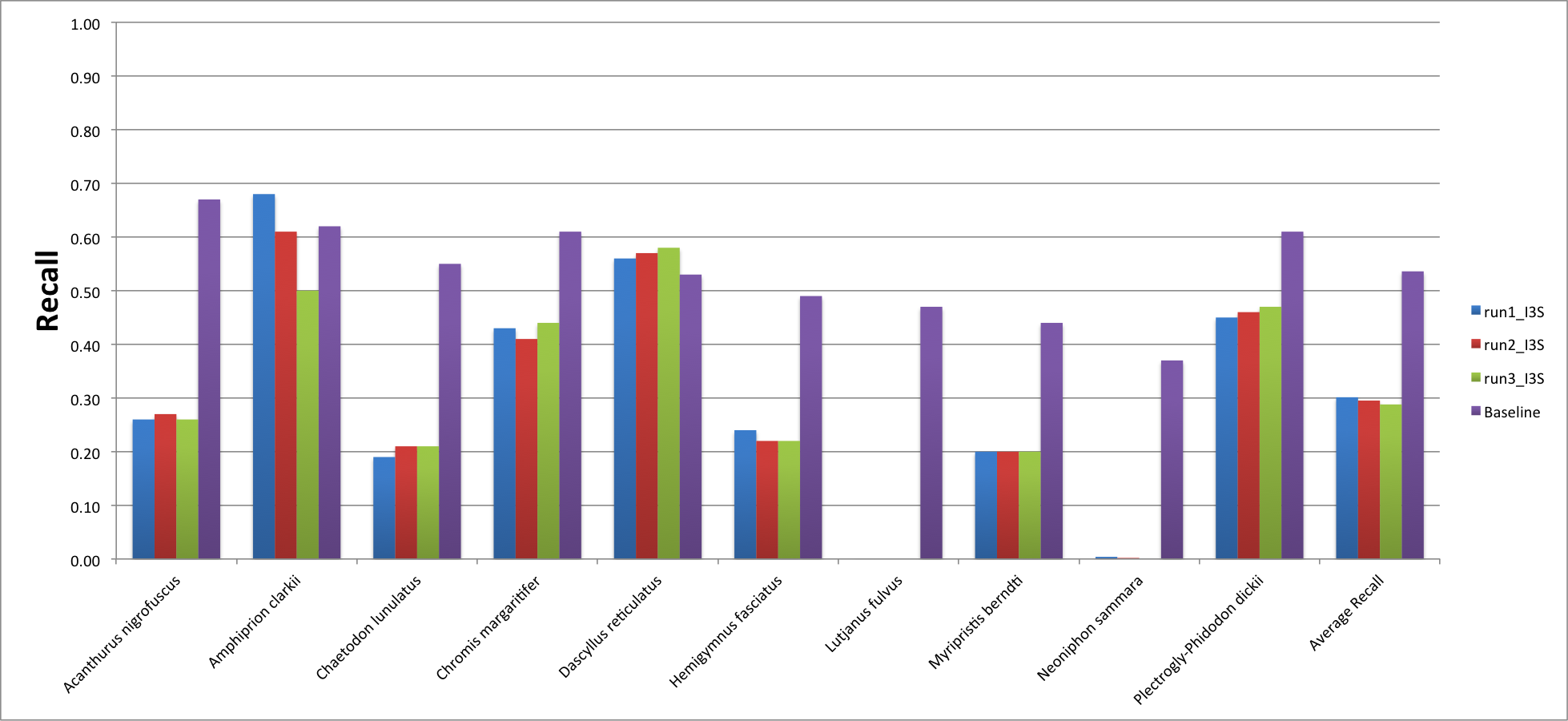
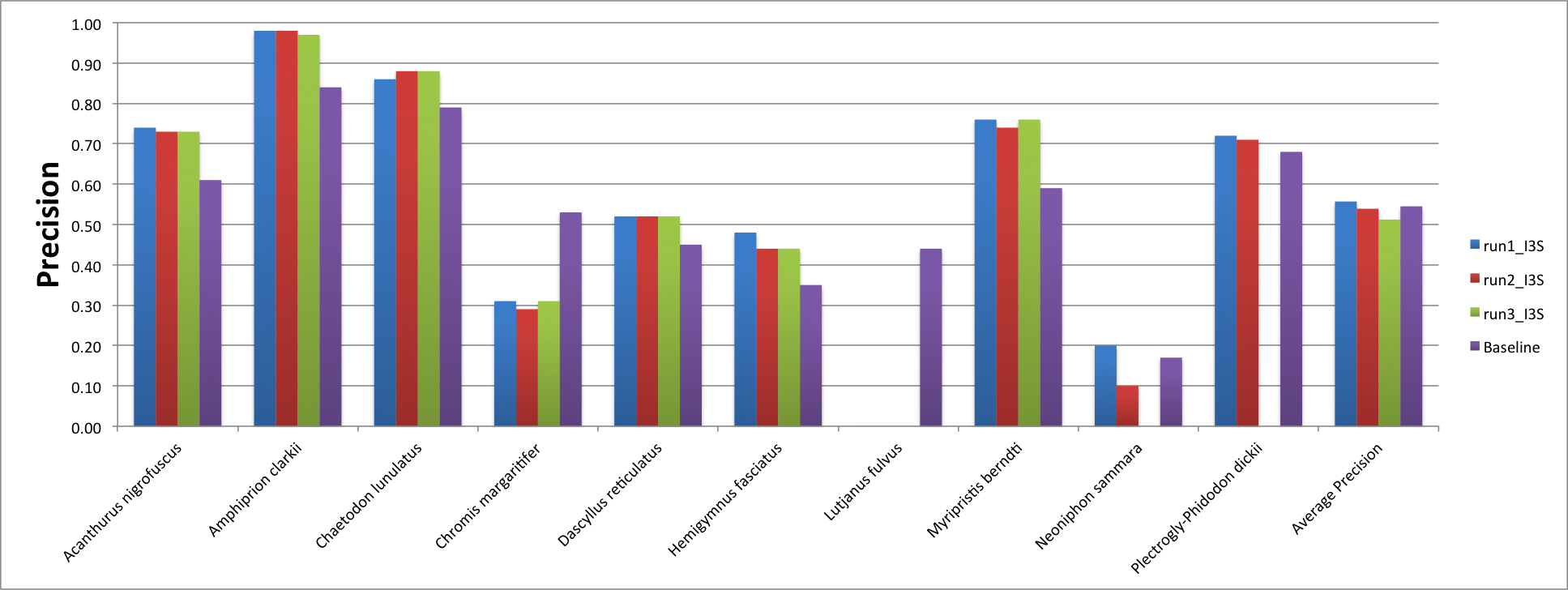
While the average recall obtained by the I3S team was lower than the baseline's one, the precision was improved.
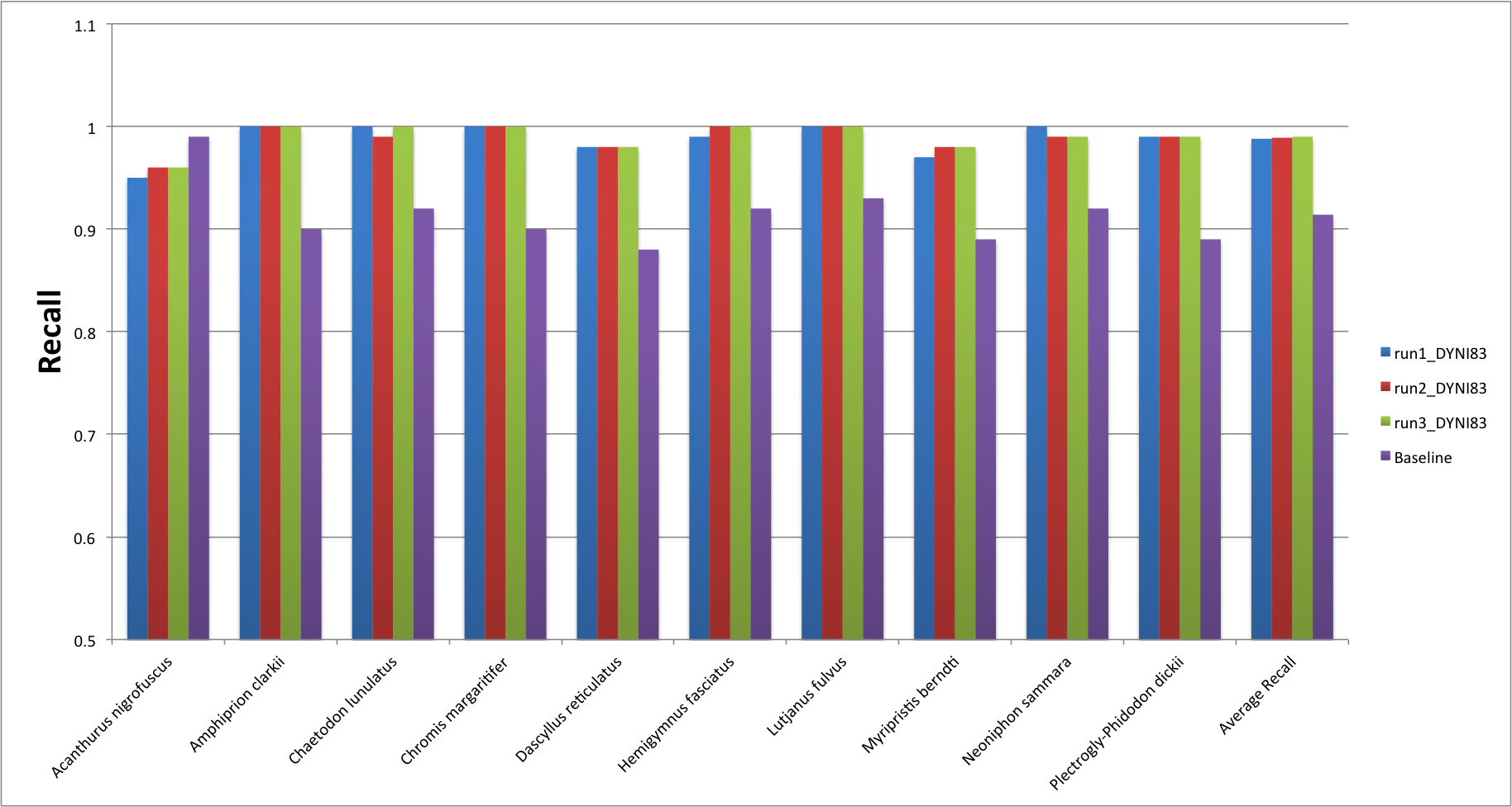
The results obtained by the DYNI83 team for subtask 4 are instead the following.
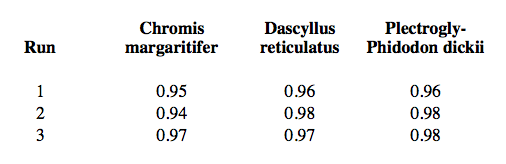
As for the precision, the DYNI83 team yielded a precision of 1 for almost all species expect for Chromis margaritifer, Dascyllus reticulatus and Plectrogly-Phidodon dickii species:
Please note the image-based recognition task (subtask4) was easier than subtask 3 since the dataset contained many near duplicate images (all detections of a fish trajectory), although the DYNI83 was able to outperform sensibly our baseline (many many congratulations for the great work!!!).
For I3S team, it has to be noticed that the performance in terms of fish species recognition (based only on the correctly detected bounding boxes) was comparable to our baseline (more numbers will come soon).
Thanks to all teams and the constructive feedbacks received by other people interested in our underwater video dataset.
We have just completed the labelling of other 25 species and we are working on removing the near duplicates from the dataset to make the fish identification and recognition task more challenging.
References for the baselines
- Barnich, O.; Van Droogenbroeck, M., "ViBe: A Universal Background Subtraction Algorithm for Video Sequences," Image Processing, IEEE Transactions on , vol.20, no.6, pp.1709,1724, June 2011
- Vedaldi, A., Fulkerson, B.: VLFeat - an open and portable library of computer vision algorithms. In: ACM International Conference on Multimedia. (2010)
How to register for the task
LifeCLEF will use the ImageCLEF registration interface. Here you can choose a user name and a password. This registration interface is for example used for the submission of runs. If you already Schedule
- 01.12.2013: Registration opens (register here)
- 05.02.2014 : training data and task details release
- 09.04.2014: test data release
- 22.05.2014 deadline for submission of runs
- 30.05.2014: release of results
- 07.06.2014: deadline for submission of working notes
- 15-19.09.2014: CLEF 2014 Conference (Sheffield, UK)
Contacts
Concetto Spampinato (University of Catania, Italy): cspampin[at]dieei[dot]unict[dot]it
Robert Bob Fisher (University of Edinburgh): rbf[at]inf[dot]ed[dot]ac[dot].uk
Bas Boom (University of Edinburgh): bboom[at]inf[dot]ed[dot]ac[dot].uk
| Attachment | Size |
|---|---|
| 388.49 KB | |
| 15.59 KB | |
| 350.36 KB | |
| 367.58 KB | |
| 551.98 KB | |
| 20.09 KB |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}