- ImageCLEF 2026
- LifeCLEF 2026
- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
ImageCLEFfusion
Motivation
While deep neural network methods have proven their predictive power in a large number of tasks, there still are a number of particular domains where a single deep learning network is not enough for attaining high precision. Of course, this phenomenon has further repercussions, as it may impede future development or even market integration and adoption for methods that target those particular tasks and domains. Late fusion (also called ensembling or decision-level fusion) represents one of the methods that researchers in machine learning employ in order to increase the performance of single-system approaches. It consists of using a series of weaker learner methods called inducers, that are trained and tested on the dataset, whose prediction outputs are combined in the final step, via a fusion method (also called ensembling method or strategy) in order to create a new and improved set of predictions. These systems have a long history and are shown to be particularly useful in scenarios where the performance of single-system approaches is not considered satisfactory.
The usefulness of ensembling methods has been proved in a large number of tasks in the current literature. To this point, these approaches have been successful even with a low number of inducers, in traditional tasks such as video action recognition [Sudhakaran2020]. However, the ImageCLEFfusion 2023 task proposes some differences to these kinds of approaches.
First of all, we propose to focus this task on the prediction of a couple of subjective concepts, where ground truth is not absolute and may be different for different annotators. Therefore, we choose the prediction of media interestingness and search result diversification. Secondly, we wish to explore the power of late fusion approaches as much as possible, and therefore propose to provide a set of prediction results extracted from a very large number of inducers.
We are interested in exploring a number of aspects of fusion approaches for this task, including but not limited to: the performance of different fusion methods, methods for selecting inducers from a larger given set of inducers, the exploitation of positive and negative correlations between inducers, etc.
For this second edition of the task, we propose going forward with the two datasets we previously explored, based on regression and retrieval and add new data, representing a new machine learning paradigm, namely multi-class labeling.
Recommended reading
There are many published works on general fusion systems, however, we recommend two valuable works that analyze the current literature on ensembling [Gomes2017, Sagi2018]. Also, a number of works analyze a set of novel approaches that directly use deep neural networks as the primary ensembling methods [Ştefan2020, Constantin2021a]. Finally, [Constantin2022] presents an in-depth analysis of the way ensembling methods can be applied to the prediction of media interestingness. This is by no means an exhaustive list of works on late fusion, but we believe it is a strong starting point for studying this domain.
News
More information will be added soon!
Task Description
In a general sense, ensembling systems are represented by an algorithm or function F that, given a set S composed of M samples, and a set A composed of N inducers that output a vector of N predictions for each sample, is able to create a newer and better set of predictions for the set of samples by combining the outputs for each individual sample.
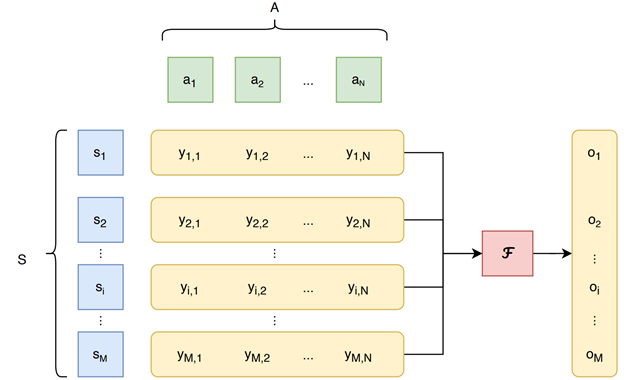
As mentioned, we provide two types of data for ImageCLEFfusion, generating two tasks, related to:
- media interestingness (ImageCLEFfusion-int), a regression task
- result diversification (ImageCLEFfusion-div), a retrieval task
- medical image captioning (ImageCLEFfusion-cap), a multi-class labeling task
For ImageCLEFfusion, we will provide the outputs of the inducers associated with the media samples. The use of external data is prohibited for the two tasks, as well as the development and the use of any additional inducers other than the ones we provide. In this way we want to ensure a fair comparison of the fusion method and inducer selection principles without any variations in the inducer set.
Data
ImageCLEFfusion-int. The data for this task is extracted and corresponds to the Interestingness10k dataset [Constantin2021b]. We will provide output data from 33 inducers, while 1826 samples will be used for the development set, and 609 samples will be used for the testing set.
ImageCLEFfusion-div. The data for this task is extracted and corresponds to the Retrieving Diverse Social Images Task dataset [Ionescu2020]. We will provide outputs data from 117 inducers, while 104 queries will be used for the development set, and 35 samples will be used for the testing set.
ImageCLEFfusion-cap. The data for this task is extracted and corresponds to the ImageCLEF Medical Caption Task. We will provide outputs data from 84 inducers for 6101 images for the development set, and for 1500 images for the testing set.
Evaluation methodology
Evaluation will be performed by using the metrics specific to each dataset we use. Therefore, we will use MAP@10 for the Interestingness10k dataset (ImageCLEFfusion-int task), F1 and Cluster Recall at 20 for the diversity dataset (ImageCLEFfusion-div task), and F1 for the medical captioning dataset (ImageCLEFfusion-cap task). We will provide scripts that will help you calculate these metrics and instructions with regards to file structure.
Participant registration
Please refer to the general ImageCLEF registration instructions
Preliminary Schedule
- 17.05.2023: Deadline for submitting your runs
- 19.05.2023: Release of the processed results by the task organizers
- 05.06.2023: Deadline for submission of working notes papers by the participants
- 23.06.2023: Notification of acceptance of the working notes papers
- 07.07.2023: Camera ready working notes papers
Submission Instructions
More information will be added soon!
Results
More information will be added soon!
CEUR Working Notes
All participating teams with at least one graded submission, regardless of the score, should submit a CEUR working notes paper.
Citations
When referring to ImageCLEF 2023, please cite the following publication:
Bogdan Ionescu, Henning Müller, Ana-Maria Drăgulinescu, Wen-wai Yim, Asma Ben Abacha, Neal Snider, Griffin Adams, Meliha Yetisgen, Johannes Rückert, Alba García Seco de Herrera, Christoph M. Friedrich, Louise Bloch, Raphael Brüngel, Ahmad Idrissi-Yaghir, Henning Schäfer, Steven A. Hicks, Michael Alexander Riegler, Vajira Thambawita, Andrea Storås, Pål Halvorsen, Nikolaos Papachrysos, Johanna Schöler, Debesh Jha, Alexandra-Georgiana Andrei, Ahmedkhan Radzhabov, Ioan Coman, Vassili Kovalev, Alexandru Stan, George Ioannidis, Hugo Manguinhas, Liviu-Daniel Ștefan, Mihai Gabriel Constantin, Mihai Dogariu, Jérôme Deshayes, Adrian Popescu, Overview of the ImageCLEF 2023: Multimedia Retrieval in Medical, Social Media and Recommender Systems Applications, in Experimental IR Meets Multilinguality, Multimodality, and Interaction.Proceedings of the 14th International Conference of the CLEF Association (CLEF 2023), Springer Lecture Notes in Computer Science LNCS, Thessaloniki, Greece, September 18-21, 2023.
BibTex:
@inproceedings{ImageCLEF2023,
title = {{Overview of ImageCLEF 2023}: Multimedia Retrieval in Medical, Social Media, and Recommender Systems Applications},
author = {Bogdan Ionescu and Henning M{\"{u}}ller and Ana-Maria Dr{\u{a}}gulinescu and Wen-wai Yim and Asma Ben Abacha and Neal Snider and Griffin Adams and Meliha Yetisgen and Johannes R{\"{u}}ckert and Alba Garc{\'{\i}}a Seco de Herrera and Christoph M. Friedrich and Louise Bloch and Raphael Br{\"{u}}ngel and Ahmad Idrissi-Yaghir and Henning Sch{\"{a}}fer and Steven A. Hicks and Michael Alexander Riegler and Vajira Thambawita and Andrea Stor{\r{a}}s and P{\aa}l Halvorsen and Nikolaos Papachrysos and Johanna Sch{\"{o}}ler and Debesh Jha and Alexandra-Georgiana Andrei and Ahmedkhan Radzhabov and Ioan Coman and Vassili Kovalev and Alexandru Stan and George Ioannidis and Hugo Manguinhas and Liviu-Daniel {\c{S}}tefan and Mihai Gabriel Constantin and Mihai Dogariu and J{\'{e}}r{\^{o}}me Deshayes and Adrian Popescu},
year = {2023},
month = {September 18-21},
booktitle = {Experimental IR Meets Multilinguality, Multimodality, and Interaction},
publisher = {Springer Lecture Notes in Computer Science (LNCS)},
pages = {},
address = {Thessaloniki, Greece},
series = {Proceedings of the 14th International Conference of the CLEF Association (CLEF 2023)}
}
When referring to ImageCLEFfusion 2023 general goals, results, etc., please cite the following publication:
Liviu-Daniel Ștefan, Mihai Gabriel Constantin, Mihai Dogariu, and Bogdan Ionescu. ‘Overview of ImageCLEFfusion 2023 Task - Testing Ensembling Methods in Diverse Scenarios’. In Experimental IR Meets Multilinguality, Multimodality, and Interaction. CEUR Workshop Proceedings (CEUR-WS.org), Thessaloniki, Greece, September 18-21, 2023.
BibTex:
@inproceedings{ImageCLEFfusionOverview2023,
title = {Overview of ImageCLEFfusion 2023 Task - Testing Ensembling Methods in Diverse Scenarios},
author = {Liviu-Daniel {\c{S}}tefan and Mihai Gabriel Constantin and Mihai Dogariu and Bogdan Ionescu},
year = {2023},
month = {September 18-21},
booktitle = {Experimental IR Meets Multilinguality, Multimodality, and Interaction},
publisher = {CEUR-WS.org},
address = {Thessaloniki, Greece},
series = {CEUR Workshop Proceedings}
}
References
- [Sudhakaran2020] Sudhakaran, S., Escalera, S., & Lanz, O. (2020). Gate-shift networks for video action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1102-1111).
- [Sagi2018] Sagi, O., & Rokach, L. (2018). Ensemble learning: A survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 8(4), e1249.
- [Gomes2017] Gomes, H. M., Barddal, J. P., Enembreck, F., & Bifet, A. (2017). A survey on ensemble learning for data stream classification. ACM Computing Surveys (CSUR), 50(2), 1-36.
- [Ştefan2020] Ştefan, L. D., Constantin, M. G., & Ionescu, B. (2020, June). System Fusion with Deep Ensembles. In Proceedings of the 2020 International Conference on Multimedia Retrieval (pp. 256-260).
- [Constantin2021a] Constantin, M. G., Ştefan, L. D., & Ionescu, B. (2021, June). DeepFusion: Deep Ensembles for Domain Independent System Fusion. In the International Conference on Multimedia Modeling (pp. 240-252). Springer, Cham.
- [Constantin2022] Constantin, M. G., Ştefan, L. D., & Ionescu, B. (2022). Exploring Deep Fusion Ensembling for Automatic Visual Interestingness Prediction. In Human Perception of Visual Information (pp. 33-58). Springer, Cham.
- [Constantin2021b] Constantin, M. G., Ştefan, L. D., Ionescu, B., Duong, N. Q., Demarty, C. H., & Sjöberg, M. (2021). Visual Interestingness Prediction: A Benchmark Framework and Literature Review. International Journal of Computer Vision, 1-25.
- [Ionescu2020] Ionescu, B., Rohm, M., Boteanu, B., Gînscă, A. L., Lupu, M., & Müller, H. (2020). Benchmarking Image Retrieval Diversification Techniques for Social Media. IEEE Transactions on Multimedia, 23, 677-691.
Contact
Organizers:
- Liviu-Daniel Ștefan, <liviu_daniel.stefan(at)upb.ro>, Politehnica University of Bucharest, Romania
- Mihai Gabriel Constantin, <mihai.constantin84(at)upb.ro>, Politehnica University of Bucharest, Romania
- Mihai Dogariu, <mihai.dogariu(at)upb.ro>, Politehnica University of Bucharest, Romania
- Bogdan Ionescu <bogdan.ionescu(at)upb.ro>, Politehnica University of Bucharest, Romania
Acknowledgments
This task is supported under project AI4Media, A European Excellence Centre for Media, Society and Democracy, H2020 ICT-48-2020, grant #951911.