- ImageCLEF 2026
- LifeCLEF 2026
- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
Deepfake Detection and Generation
Welcome to the 1st edition of the Deepfake Detection and Generation Task!
Motivation
Deepfakes are AI-generated media that portray real individuals and are often created to manipulate, mislead, or misinform the public. Despite significant efforts by researchers and practitioners to combat the spread of falsified media in recent years, many challenges remain, particularly in understanding how deepfakes are generated and what makes a deepfake easily detectable. While in the past the lack of quality in the generated data made it straight-forward to detect deepfakes, generative models are always evolving, resulting in very realistic deepfakes. One of the most critical issues in this field is the lack of generalization: detection models trained on existing datasets frequently fail when confronted with previously unseen deepfake techniques.
This task aims to investigate state-of-the-art deepfake detection methods and to analyze the factors that make certain deepfakes especially difficult to detect, with a particular emphasis on the generation process itself. To enable this study, the task will be conducted across two modalities: audio and images. This will allow for a more comprehensive evaluation of deepfake characteristics and detection robustness across different forms of media.
The goal of this task is to bring together researchers and practitioners working in the field of disinformation, foster the development of new methods, and gain deeper insights into how deepfakes are generated and detected.
Schedule
The subtasks for Audio and Images will run at the same time.
The two tasks (Generation and Detection) will be carried out sequentially and will not overlap.
- 26.01.2026: Registration opens for all ImageCLEF tasks
- 23.04.2026: Registration closes for all ImageCLEF tasks
- 03.03.2026: Generation task starts. Development dataset released
- 03.04.2026: Generation task ends. Deadline for submitting participant runs.
- 07.04.2026: Detection task starts. Test dataset released
- 07.05.2026: Detection task ends. Deadline for submitting participant runs
- 28.05.2026: Submission of participant papers [CEUR-WS]
- 30.06.2026: Notification of acceptance
- 21.09.2026: CLEF 2026, Jena, Germany
Task Description
The task is composed of 2 subtasks, with each one being applied to two modalities: audio or images. The sub-tasks are strongly connected, with results from one subtask being used in the evaluation of the other. Therefore, the tasks will not run at the same time: the generation task will be held first, and afterwards, the detection task. Although participation in only one subtask or only one modality is allowed, we encourage participation in both sub-tasks, as they are deeply connected. The subtasks are:
Subtask 1: Deepfake Generation (audio and images)
In this subtask, participants will generate images or short audio clips depicting specific identities from a real-world dataset. The objective is to better understand the factors that make deepfakes difficult to detect. To this end, participants will aim to produce high-quality generated deepfakes that are as realistic as possible, while still adhering to strict constraints. The task is a few-shot problem, with one video per identity as reference.
For the Images part, these constraints include a quality check, identity similarity requirements and the preservation of key features (specific facial landmarks in images).
For the Audio part, the constraints include a quality check, identity similarity requirements and a text prompt that must be spoken in the audio sequence.
The figure below presents an overview on the Generation task.
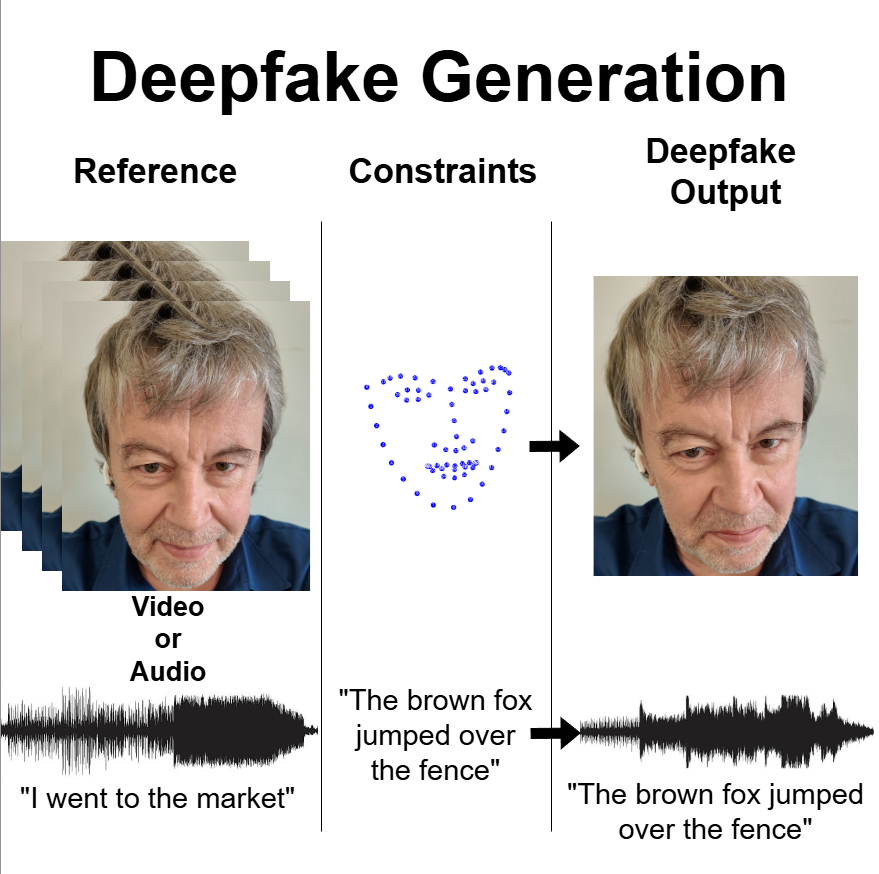
The generated data will be uploaded on our platform and will be evaluated using a range of state-of-the-art deepfake detection systems implemented by the organizers, as well as using the other participant's deepfake detection systems from Subtask 2. The best results should be as realistic as possible, adhere to the constraints and should not be detected by deepfake detection systems.
Subtask 2: Deepfake Detection (audio and images)
In this subtask, participants will be asked to assess the authenticity of images or audio files and make a binary classification: deepfake or real. The subtask aims to evaluate the strength of deepfake detectors and also their weaknesses.
The test dataset will be composed of deepfakes generated by the task organizers, deepfakes obtained from different sopurces on the internet and the deepfakes generated by the other participants in Subtask 1.
Data
Both sub-tasks are implemented for two separate modalities: audio and images.
For the Generation subtask, the participants will receive two separate datasets, for images and audio. Both datasets contain development data that will be used for the deepfake generation process.
For the Images subtask, the participants will receive a dataset composed of over 300 video clips of length between 8 and 30 seconds, depicting a single person speaking. These videos will be used as a baseline for generating deepfakes, one video per identity. The participants will also receive between 3 and 5 sets of facial landmarks coordinates for each identity. Those will be used as a constraint for image generation.
For the Audio subtask, the participants will receive a dataset of hundreds of mono audio files of different people saying different phrases, alongs with a text transcription of those phrases. The audio files will be used as a baseline for generating deepfakes, one audio file per identity. The perticipants will also receive text prompts for each identity. Those will be used as a constraint for audio generation.
For the Detection subtask, the participants will receive a dataset composed of real and deepfake data to be classified. The dataset is composed or real images/audio files of short length and deepfakes: (1) deepfakes generated by the organizers as a baseline, using state of the art methods and popular approaches, (2) deepfakes found on the internet and (3) deepfakes generated by all participants in the Generation task.
Note: Neither of the tasks will provide a Training Dataset.
The Generation task is a few-shot generation task, while the Detection task will not provide training data to make sure that model generalization is achieved (in deepfake detection, a lot of detectors suffer from the lack of generalization, due to the models learning the Generator's fingerprint instead of more general widely applicable features). For both tasks, the participents are free to use any State-of-the-art dataset available online to enhance their model's performance. Some of our recommendations include:
- Image Deepfake Detection (real videos and deepfakes): FaceForensics++, CelebDF, DeeperForensics, DFDC
- Image Deepfake Generation (real videos of people talking): AVSpeech, DH-FaceVid-1K, TalkVid
- Audio Deepfake Detection (real and deepfake audio clips of people talking): ASVspoof, WaveFake, AUDETER
- Audio Deepfake Generation (real audio clips of people talking): Anything from [OpenSLR] (LibriSpeech, MLS etc), People's Speech, Mozilla Common Voice
Evaluation Methodology
For the Generation subtask, the generated deepfakes will be scored using a combination of the following: (1) Identity similarity score (measuring how well the generated image/audio file mimics the identity of the target person), (2) Image quality score (measuring the realism of the generated image/audio file), (3) Constraints Score (how well the deepfakes satisy the imposed constraints (text promp for audio and facial landmarks position for images) and (4) Deepfake detection Score (how well the data evaded the implemented deepfake detectors), which will be split into 2: (4a) Organizer Models Detection Score and (4b) Participant Models Detection Score (from the Detection Subtask).
For the Detection subtask, the deepfake detectors will be evaluated using metrics like accuracy, recall, precision and F1 Score. The detectors will be evaluated on a test dataset composed of Real and Deepfake Images provided by the organizers, as well as on the Deepfakes generated by other teams in the Generation Subtask.
Participant registration
Please refer to the general ImageCLEF registration instructions.
Results
CEUR Working Notes
Citations
Contact
Contact person: Dan-Cristian Stanciu - dan.stanciu1203@upb.ro
Organizers
Image Generation and Detection
Dan-Cristian Stanciu, National University of Science and Technology POLITEHNICA Bucharest
Bogdan Ionescu, National University of Science and Technology POLITEHNICA Bucharest
Liviu-Daniel Ștefan, National University of Science and Technology POLITEHNICA Bucharest
Mihai-Gabriel Constantin, National University of Science and Technology POLITEHNICA Bucharest
Mihai Dogariu, National University of Science and Technology POLITEHNICA Bucharest
Audio Generation and Detection
Ana Nicolae, National University of Science and Technology POLITEHNICA Bucharest
Andrei-Radu Danila, National University of Science and Technology POLITEHNICA Bucharest
Radu-George Bolborici, National University of Science and Technology POLITEHNICA Bucharest
Marian Negru, National University of Science and Technology POLITEHNICA Bucharest
Alexandru-Florin Ene, National University of Science and Technology POLITEHNICA Bucharest
Ana-Antonia Nicolae, National University of Science and Technology POLITEHNICA Bucharest
Vlad-Mihai Vasilescu, National University of Science and Technology POLITEHNICA Bucharest
| Attachment | Size |
|---|---|
| 437.33 KB |