- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
Robot vision
Welcome to the website of the 6th edition of the Robot Vision challenge!
The 6th edition of the Robot Vision challenge follows five previous successful events. As for the previous editions, the challenge will address the problem of semantic place classification using visual and depth information including object recognition.
News
- 01.11.2013: The task has been released
- 01.04.2014: Test data has been released
- 09.04.2014: Validation data has been released
- 15.04.2014: Submission system is now open
- 01.05.2014: Submission deadline has been extended --> new date: May 5th
- 15.05.2014: Results have been released
Schedule
- 01.11.2013: Registration opens (register here)
- 16.12.2013: Development data is released (instructions to access the data)
- 01.04.2014: Test data is released (instructions to access test data)
- 09.04.2014: Validation data is released (instructions to access validation data)
- 15.04.2014: Submission system opens (instructions for submission)
- 05.04.2014: Submission system closes
- 15.05.2014: Processed submission results are released
- 07.06.2014: Deadline for submission of working notes papers
- 15.-18.09.2014: CLEF 2014, Sheffield, UK
Results
| RobotVision Challenge |
| Groups | |||||||||||||||||||||||||
|
| Runs | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Task overview
The proposal for Robot Vision 2014 task is focused on the use of multimodal information (visual and depth images) with application to semantic localization and object recognition. The main objective of this edition is to address the problem of robot localization in parallel to object recognition from a semantic point of view. Both problems are inherently related: the objects present in a scene can help to determine the room category and vice versa. Solutions presented should be as general as possible while specific proposals are not desired. In addition to the use of visual data, depth images acquired from a Microsoft Kinect device will be used, which has demonstrated to be a de facto standard in the use of depth images. In this new edition of the task, we will introduce strong variations between training and test scenarios, increasing the range application of participant proposals. Thanks to these changes, solutions presented in the task will be expected to solve the proposed challenge but also to solve the object recognition and localization problems in any environment.
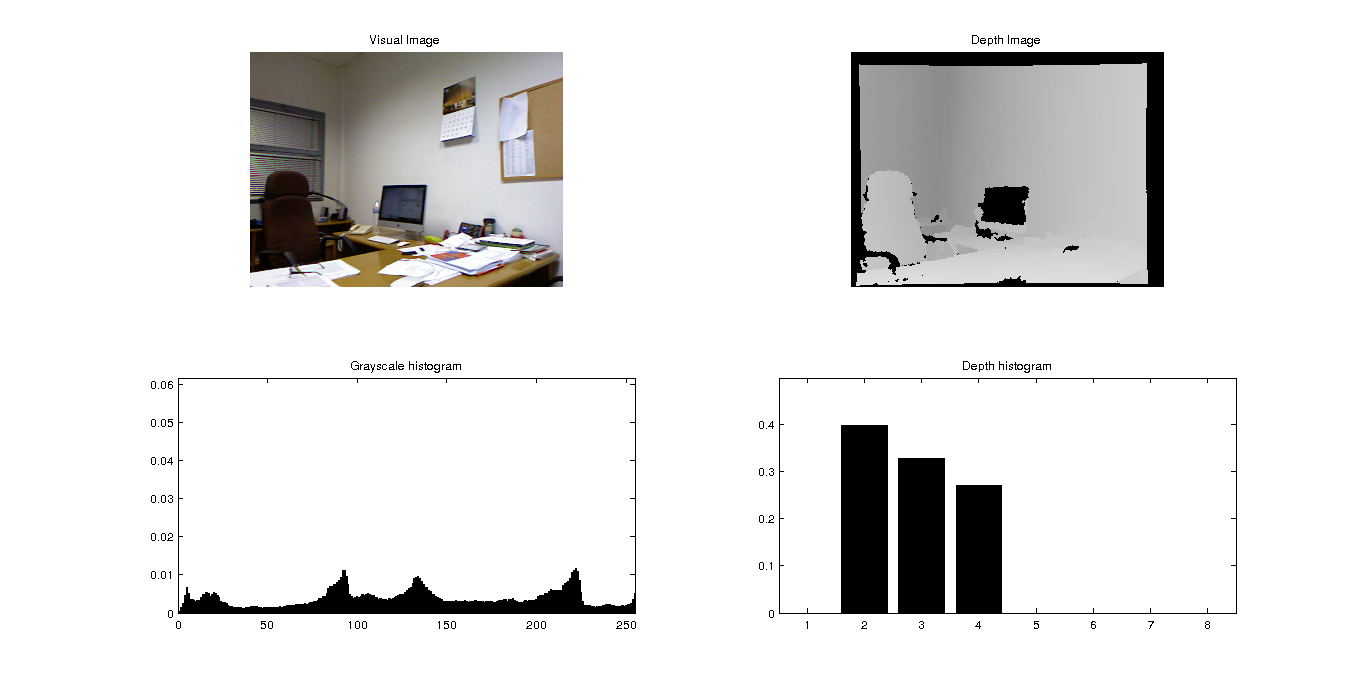
Motivation
An increasing amount of autonomous robots are expected to be built in the future to allow for ambient assisted living, responding to an aging population and a decreasing work force. In this context robots need to be able to adapt to environments, being able to localize their position based on integrated cameras and also recognize the objects that are suitable for manipulation. Place localization and object recognition can happen under very different lighting conditions (sunny and cloudy days, artificial lighting or darkness), and changing configurations on the environment distribution. That is, similar room categories and objects should be recognized in different buildings or environments, even when some of these environments have not been imaged previously. The detection of objects and the use of multimodal data through distance sensors underline the multimodal nature of the task.
What to do
A sequence of test frames has to be annotated. Each test frame consists of a visual image and a depth image (.pcd format) and the following information has to be provided: the semantic class of the room where the frame was acquired (corridor, bathroom, ...) and the list of pre-defined objects that can be identified in the scene (trash, computer, chair, ...)
Dataset description
There will be a single training sequence with 5000 visual images and 5000 depth images. These are all the rooms/categories that appear in the database:
- Corridor
- Hall
- ProfessorOffice
- StudentOffice
- TechnicalRoom
- Toilet
- Secretary
- VisioConferene
- Warehouse
- ElevatorArea

Sample images for all the room categories listed in the dataset
Objects
These are all the objects that can appear in any image of the database:
- Extinguisher
- Phone
- Chair
- Printer
- Urinal
- Bookself
- Trash
- Fridge

Sample images for all the objects listed in the dataset
Registering for the task and accessing the data
To participate in this task, please register by following the instructions found in the main ImageCLEF 2014 webpage.
All training datasets can be downloaded from
- Visual images: download here
- Depth Images: download here
- Robot Vision script: download here
Validation data
In order to allow participants to evaluate their proposals with new sequences, we have created a new validation sequence (1500 images). This sequence includes new images of a non-previously seen building that presents similar room categories and objects as for the training sequences. Test sequence also includes images from this new building. Therefore, participants proposals are expected to cope with this situation.This new dataset can be downloaded from
- Visual images: download here
- Depth Images: download here
- MATLAB script: download here
Test data
The test dataset can be downloaded from
- Visual images: download here
- Depth Images: download here
- MATLAB script: download here
Participants have to process the test dataset and classify the room category and objects appearance for each frame. This is done by uploading submission files to the ImageCLEF system (see section below). Submission files can be directly generated when using the MATLAB script. Such script is similar to the original one but it includes the configuration for using test sequence.
If participants prefer to directly generate valid submission files, they have to present the following format:
...
14 Unknown Extinguisher !Chair !Printer Bookshelf Urinal Trash Phone Fridge
15 StudentOffice Extinguisher !Chair !Printer Bookshelf Urinal Trash Phone Fridge
...
where Unknown is used when the room category is not classified. !Object is used to select that the Object does not appear in the scene. Object is used to select that the Object appears in the scene.
Submission instructions
The submissions will be received through the ImageCLEF 2014 system, going to "Runs" and then "Submit run" and select track "ImageCLEF:RobotVision".
Evaluation methodology
For each frame in the test sequence, participants have to provide information related to the class/room category but also related to the presence of the objects listed in the dataset. The number of times a specific object appears in a frame it is not relevant. The final score for a run will be the sum of all the scores obtained for the frames included in the test sequence.
The following rules are used when calculating the final score for a frame:
Class/Room Category
- The class/room category has been correctly classified: +1.0 points
- The class/room category has been wrongly classified: -0.5 points
- The class/room category has not been classified: 0.0 points
Object
- For each object correctly detected (True Positive): +1.0 points
- For each object incorrectly detected (False Positive): -0.25 points points
- For each object correctly detected as not present (True Negative) : 0.0 points
- For each object incorrectly detected as not present (False Negative) : -0.25 points points
Example
Three example of performance evaluation for a single test frame are exposed in the following lines.
Real values for the frame: A TechnicalRoom with two type of objects appearing in the scene: Phone and Printer. Maximum Score: 3.0
| Class / Room Category | Extinguisher | Phone | Chair | Printer | Urinal | Bookself | Trash | Fridge |
| TechnicalRoom | NO | YES | NO | YES | NO | NO | NO | NO |
| Class / Room Category | Extinguisher | Phone | Chair | Printer | Urinal | Bookself | Trash | Fridge |
| TechnicalRoom | NO | YES | NO | NO | NO | NO | YES | NO |
| 1.0 | 0.0 | 1.0 | 0.0 | -0.25 | 0.0 | 0.0 | -0.25 | 0.0 |
| Class / Room Category | Extinguisher | Phone | Chair | Printer | Urinal | Bookself | Trash | Fridge |
| Unknown | NO | YES | NO | YES | NO | NO | NO | NO |
| 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Class / Room Category | Extinguisher | Phone | Chair | Printer | Urinal | Bookself | Trash | Fridge |
| Corridor | YES | NO | NO | YES | NO | NO | NO | NO |
| -0.5 | -0.25 | -0.25 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
Organizers
- Jesus Martinez Gomez, University of Castilla-La Mancha, Albacete, Spain, jesus.martinez@uclm.es
- Ismael Garcia Varea, University of Castilla-La Mancha, Albacete, Spain, Ismael.Garcia@uclm.es
- Miguel Cazorla, University of Alicante, Alicante, Spain, miguel@dccia.ua.es
- Vicente Morell, Research Institute, University of Alicante, Alicante, Spain, vmorell@dccia.ua.es
CLEF
ImageCLEF lab and all its tasks are part of the Cross Language Evaluation Forum: CLEF 2014  | |