- ImageCLEF 2026
- LifeCLEF 2026
- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
GeoLifeCLEF 2018
 |
We found a bug in the dataset of this challenge. We discourage using it anymore since it could lead to erroneous conclusions. Actually, all the environmental patches having some overlap with the sea contain information mistakenly copied from other patches instead of the undefined values of the sea pixels. In some cases, this information is directly correlated with the patches of the same species in the training set. |
|---|
Usage scenario
Automatically predicting the list of species that are the most likely to be observed at a given location is useful for many scenarios in biodiversity informatics. First of all, it could improve species identification processes and tools by reducing the list of candidate species that are observable at a given location (be they automated, semi-automated or based on classical field guides or flora). More generally, it could facilitate biodiversity inventories through the development of location-based recommendation services (typically on mobile phones) as well as the involvement of non-expert nature observers. Last but not least, it might serve educational purposes thanks to biodiversity discovery applications providing functionalities such as contextualized educational pathways.
Challenge
The aim of the challenge is to predict the list of species that are the most likely to be observed at a given location. Therefore, we will provide a large training set of species occurrences, each occurrence being associated to a multi-channel image characterizing the local environment. Indeed, it is usually not possible to learn a species distribution model directly from spatial positions because of the limited number of occurrences and the sampling bias. What is usually done in ecology is to predict the distribution on the basis of a representation in the environmental space, typically a feature vector composed of climatic variables (average temperature at that location, precipitation, etc.) and other variables such as soil type, land cover, distance to water, etc. The originality of GeoLifeCLEF is to generalize such niche modeling approach to the use of an image-based environmental representation space. Instead of learning a model from environmental feature vectors, the goal of the task will be to learn a model from k-dimensional image patches, each patch representing the value of an environmental variable in the neighborhood of the occurrence (see figure below for an illustration). From a machine learning point of view, the challenge will thus be treatable as an image classification task.
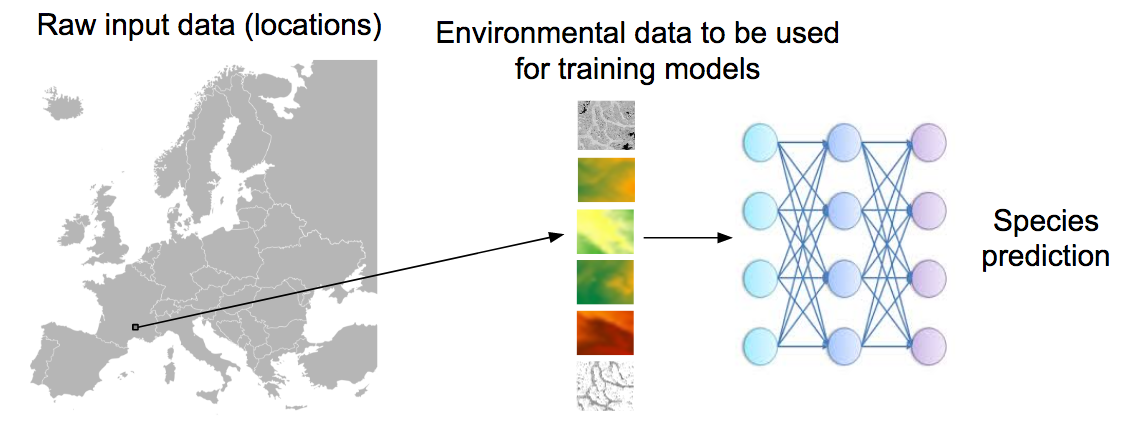
Data
A detailed description of the protocol used to build the datasets is given in the file GLC18_Protocol_note.pdf, downloadable on this page. In a nutshell, the dataset was built from occurrence data of the Global Biodiversity Information Facility (GBIF), the world’s largest open data infrastructure in this domain, funded by governments. It is composed of 291,392 occurrences of 3,336 plant species observed on the French territory between 1835 and 2017 (DOIs: https://doi.org/10.15468/dl.vqsrdc and https://doi.org/10.15468/dl.wrhgft). Each occurrence is characterized by 33 local environmental images of 64x64 pixels. These environmental images were constructed from various open datasets including Chelsea Climate [1], ESDB soil pedology data [2,3,4], Corine Land Cover 2012 soil occupation data, CGIAR-CSI evapotranspiration data [5,6], USGS Elevation data (Data available from the U.S. Geological Survey.) and BD Carthage hydrologic data. This dataset is split in 3/4 for training and 1/4 for testing.
External data
Participants are allowed to use other external training data but at the condition that (i) the experiment is entirely re-produceable, i.e. that the used external ressource is clearly referenced and accessible to any other research group in the world, (ii) participants submit at least one run without external training data so that we can study the contribution of such ressources, (iii) the additional ressource does not contain any of the test observations.
Metric
The used metric will be the Mean Reciprocal Rank (MRR). The MRR is a statistic measure for evaluating any process that produces a list of possible responses to a sample of queries (spatial occurrences in our case), ordered by probability of correctness. The reciprocal rank of a query response is the multiplicative inverse of the rank of the first correct answer. The MRR is the average of the reciprocal ranks for the whole test set:
where |Q| is the total number of query occurrences in the test set.

Registration and data access
Please refer to the general LifeCLEF registration instructions
The train and TEST datasets, as well as the ground truth of the test set can be downloaded at : http://otmedia.lirmm.fr/LifeCLEF/GeoLifeCLEF2018/
The ground truth file is called gt_file.csv. It contains two columns, the first is the patch_id of the occurrence, while the second is the species_glc_id.
Results
|
We found a bug in the dataset of this challenge so the following results might be biased. Actually, all the environmental patches having some overlap with the sea contain information mistakenly copied from other patches instead of the undefined values of the sea pixels. In some cases, this information is directly correlated with the patches of the same species in the training set. |
|---|
The following table sum up the MRR results per participant:
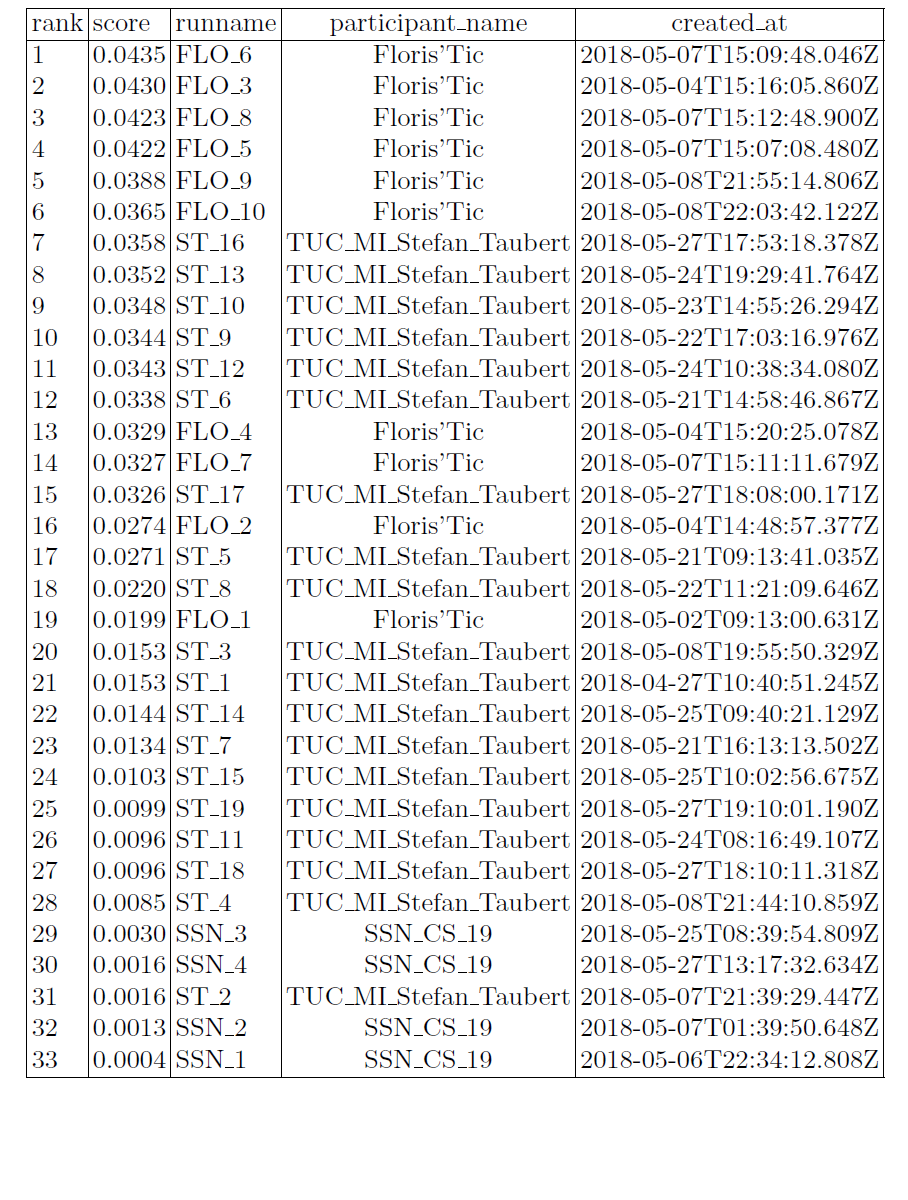
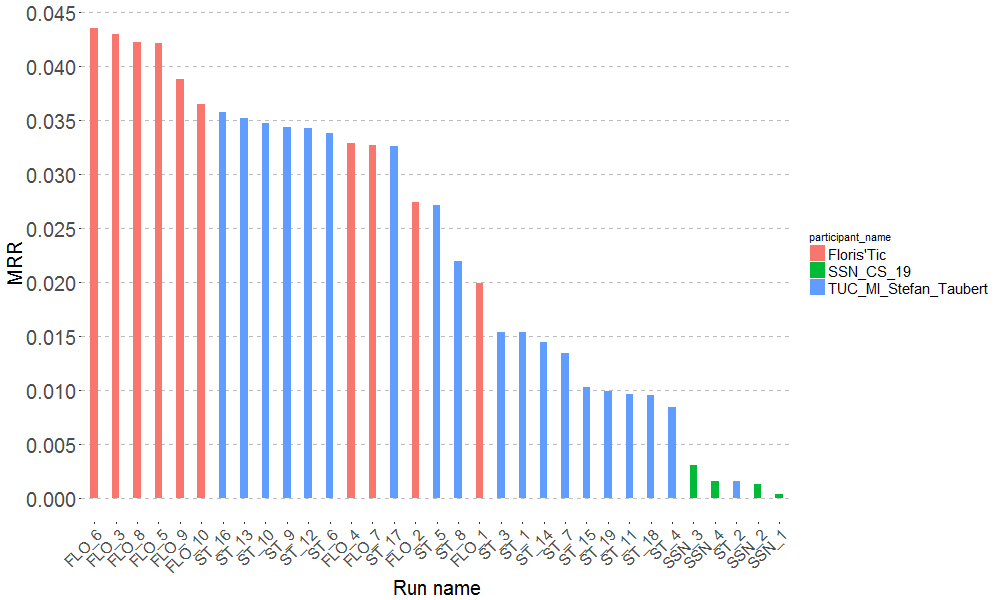
Alternatively, they are gathered in the pretty graph below:
References
[1] Karger, Dirk Nikolaus, Conrad, Olaf, Böhner, Jürgen, Kawohl, Tobias, Kreft, Holger, Soria-Auza,
Rodrigo Wilber, Zimmermann, Niklaus, Linder, H Peter, & Kessler, Michael. 2016. Climatologies
at high resolution for the earth’s land surface areas. arXiv preprint arXiv :1607.00217.
[2] Panagos, Panos. 2006. The European soil database. GEO : connexion, 5(7), 32–33.
[3] Panagos, Panos, Van Liedekerke, Marc, Jones, Arwyn, & Montanarella, Luca. 2012. European Soil
Data Centre : Response to European policy support and public data requirements. Land Use Policy,
29(2), 329–338.
[4] Van Liedekerke, M, Jones, A, & Panagos, P. 2006. ESDBv2 Raster Library-a set of rasters derived
from the European Soil Database distribution v2. 0. European Commission and the European Soil
Bureau Network, CDROM, EUR, 19945.
[5] Zomer, Robert J, Bossio, Deborah A, Trabucco, Antonio, Yuanjie, Li, Gupta, Diwan C, & Singh,
Virendra P. 2007. Trees and water : smallholder agroforestry on irrigated lands in Northern India.
Vol. 122. IWMI.
[6] Zomer, Robert J, Trabucco, Antonio, Bossio, Deborah A, & Verchot, Louis V. 2008. Climate change
mitigation : A spatial analysis of global land suitability for clean development mechanism afforestation
and reforestation. Agriculture, ecosystems & environment, 126(1), 67–80.
| Attachment | Size |
|---|---|
| 1.25 MB | |
| 382.01 KB |