- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
ExperLifeCLEF 2018
| News |
| A direct link to the overview of the task: Overview of ExpertLifeCLEF 2018: how far Automated Identification Systems are from the Best Experts?, Hervé Goëau, Pierre Bonnet, Alexis Joly, LifeCLEF 2018 working notes, Avignon, France |
| Link to the data https://lab.plantnet.org/LifeCLEF/ExpertCLEF2018/ExpertCLEF2018.tar.gz |
| Best performing models made available by CVUT: In order to support research in fine-grained plant classification, CVUT share the trained Inception-v4 and Inception-ResNet-v2 CNN models from their winning submission to ExpertLifeCLEF 2018: Access models |
Usage scenario
Automated identification of plants and animals has improved considerably in the last few years. In the scope of LifeCLEF 2017 in particular, we measured impressive identification performance achieved thanks to recent deep learning models (e.g. up to 90% classification accuracy over 10K species). This raises the question of how far automated systems are from the human expertise and of whether there is a upper bound that can not be exceeded. A picture actually contains only a partial information about the observed plant and it is often not sufficient to determine the right species with certainty. For instance, a decisive organ such as the flower or the fruit, might not be visible at the time a plant was observed. Or some of the discriminant patterns might be very hard or unlikely to be observed in a picture such as the presence of pills or latex, or the morphology of the root. As a consequence, even the best experts can be confused and/or disagree between each others when attempting to identify a plant from a set of pictures. Similar issues arise for most living organisms including fishes, birds, insects, etc. Quantifying this intrinsic data uncertainty and comparing it to the performance of the best automated systems is of high interest for both computer scientists and expert naturalists.
Data Collection
To conduct a valuable experts vs. machines experiment, we collected image-based identifications from the best experts in the plant domains. Therefore, we created sets of observations that were identified in the field by other experts (in order to have a near-perfect golden standard). These pictures will be immersed in a much larger test set that will have to be processed by the participating systems. As for training data, the datasets of the previous LifeCLEF campaigns will be made available to the participants and might be extended with new contents. It will contain between 1M and 2M pictures.
Task overview
The goal of the task will be to return the most likely species for each observation of the test set. The small fraction of the test set identified by the pool of experts will then be used to conduct the experts vs. machines evaluation.
Metric
The main evaluation metric will be the top-1 accuracy.
Results
A total of 4 participating groups submitted 19 runs. Thanks to all of you for your efforts!
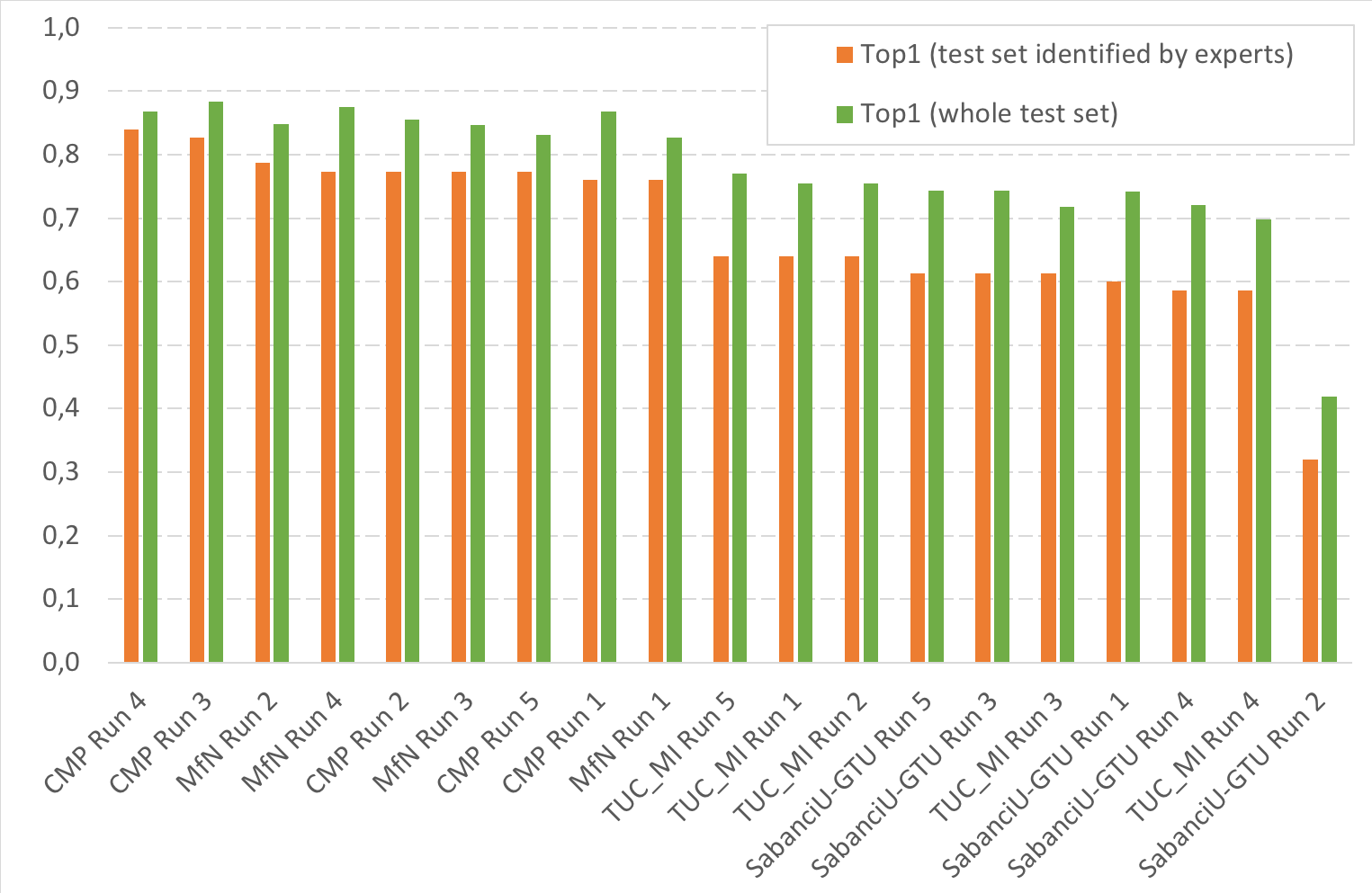
The following table reports the Top1 accuracy on the whole test set and the small fraction of the test set identified by the pool of experts. Last lines of the table report the results obtained by the human experts.
| Team run | filename | Top1 (test set identified by experts) | Top1 (whole test set) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CMP Run 4 | 8ab3be8c-d9f5-4136-acf0-1077f6aa69e6_CMP_run4_ensemble6noisy_cropmirror_em.txt | 0,840 | 0,867
| CMP Run 3 |
e7ea848e-5b55-4028-ade4-d69e8c7fc5a3_CMP_run3_ensemble12_cropmirror_em.txt |
0,827 |
0,884
| MfN Run 2 |
5344c019-d34d-4b57-8588-84bce354238e_LifeClef2018ExpertMfN02.csv |
0,787 |
0,848
| MfN Run 4 |
8b66e762-6881-435f-a670-d28a1d6d0b1a_LifeClef2018ExpertMfN04.csv |
0,773 |
0,875
| CMP Run 2 |
ab2ed3df-79c9-4b5d-b905-909528756d52_CMP_run2_ensemble6clean_cropmirror.txt |
0,773 |
0,856
| MfN Run 3 |
eccbf7d7-135e-42bd-a089-25df95cea4bb_LifeClef2018ExpertMfN03.csv |
0,773 |
0,847
| CMP Run 5 |
c65f02ce-86cf-4d9b-b35d-b7a19cf0d505_CMP_run5_singlemodel_v4m_cropmirror_em.txt |
0,773 |
0,832
| CMP Run 1 |
bdc094a7-cacc-4bcb-ad3a-afbacd578904_CMP_run1_ensemble6clean_cropmirror_em.txt |
0,760 |
0,868
| MfN Run 1 |
6df79608-da2d-4398-b149-d2febc640ffb_LifeClef2018ExpertMfN01.csv |
0,760 |
0,826
| TUC_MI-Josef_Haupt Run 5 |
9a279651-25d0-426d-9cdb-c76fb35ffcec_submission.csv |
0,640 |
0,770
| TUC_MI-Josef_Haupt Run 1 |
4cb00cee-0a93-4580-b9d2-86ca820d627b_r1_i8_d13_d16_d17.csv |
0,640 |
0,755
| TUC_MI-Josef_Haupt Run 2 |
f4f992bb-7963-4662-ab8d-2b7e7fb016b2_r1_i8_d13_d16_d17_top10_submission.csv |
0,640 |
0,755
| SabanciU-GTU Run 5 |
ea163085-c7f0-405e-b702-de1fb6b03b89_SabanciU-GTU_4.csv |
0,613 |
0,744
| SabanciU-GTU Run 3 |
5d998f18-c3b7-42e5-8748-6553aa2e554b_SabanciU-GTU_tags.csv |
0,613 |
0,743
| TUC_MI-Josef_Haupt Run 3 |
fe900efb-e4d2-4957-ac05-2ce530d7c321_submission.csv |
0,613 |
0,718
| SabanciU-GTU Run 1 |
bbf6d0ad-cabb-4304-bc59-a8b2a2687764_SABANCIUNIVERSITY_RUN1.csv |
0,600 |
0,741
| SabanciU-GTU Run 4 |
29f422de-28ae-44a5-bcb0-2e21176fadaa_SabanciU-GTU_DeepandECOC.csv |
0,587 |
0,721
| TUC_MI-Josef_Haupt Run 4 |
909b3512-cfdd-4674-8259-77660cece4b9_submission.csv |
0,587 |
0,698
| SabanciU-GTU Run 2 |
6fd44ea9-07e0-4f5d-b495-f82e532a63ae_official_2018_verimClefEcoc.csv |
0,320 |
0,418
| Expert 1 |
Expert 1.csv |
0,96 |
-
| Expert 2 |
Expert 2.csv |
0,933 |
-
| Expert 3 |
Expert 3.csv |
0,88 |
-
| Expert 4 |
Expert 4.csv |
0,84 |
-
| Expert 5 |
Expert 5.csv |
0,8 |
-
| Expert 6 |
Expert 6.csv |
0,773 |
-
| Expert 7 |
Expert 7.csv |
0,72 |
-
| Expert 8 |
Expert 8.csv |
0,64 |
-
| Expert 9 |
Expert 9.csv |
0,613 |
-
| |
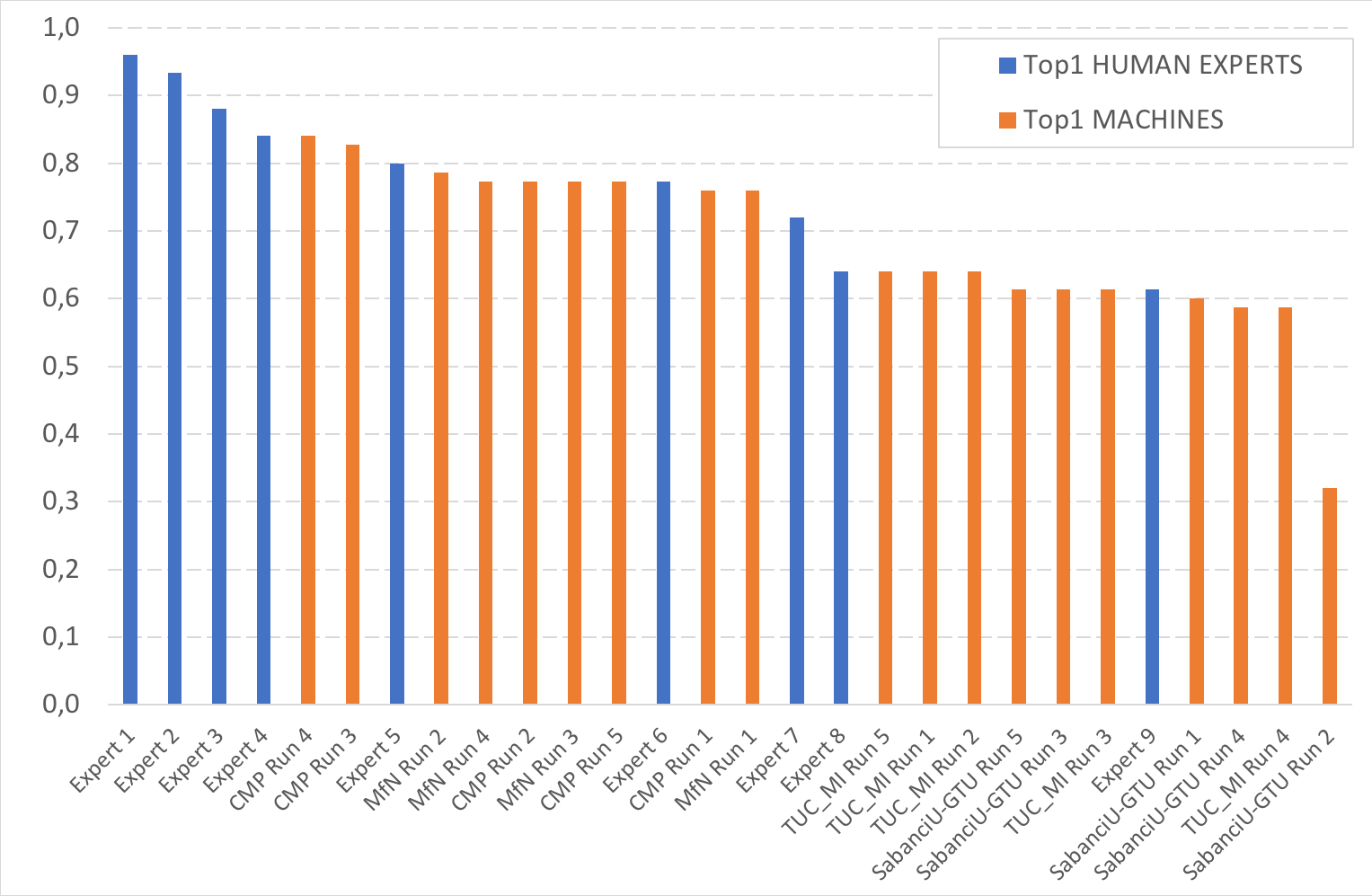
The following figure reports the comparison of the Top-1 accuracy between the "machines" and the human experts.
| Attachment | Size |
|---|---|
| 298.98 KB | |
| 132.21 KB | |
| 133.97 KB |
{kind=link}
{kind=link}
{kind=link}