- ImageCLEF 2026
- LifeCLEF 2026
- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
ImageCLEFmed MEDVQA-GI
Motivation
Welcome to the Medical Visual Question Answering for GI Task - MEDVQA-GI
Identifying lesions in colonoscopy images is one of the most popular applications of artificial intelligence in medicine. Until now, the research has focused on single-image or video analysis. With this task, we aim at bringing a new aspect to the field by adding multiple modalities to the picture. The main focus of the task will be on visual question answering and visual question generation. The goal is that through the combination of text and image data the output of the analysis gets easier to use by medical experts. The task has three sub-tasks.
- For the visual question answering (VQA), the participants need to combine images and text answers to answer the questions.
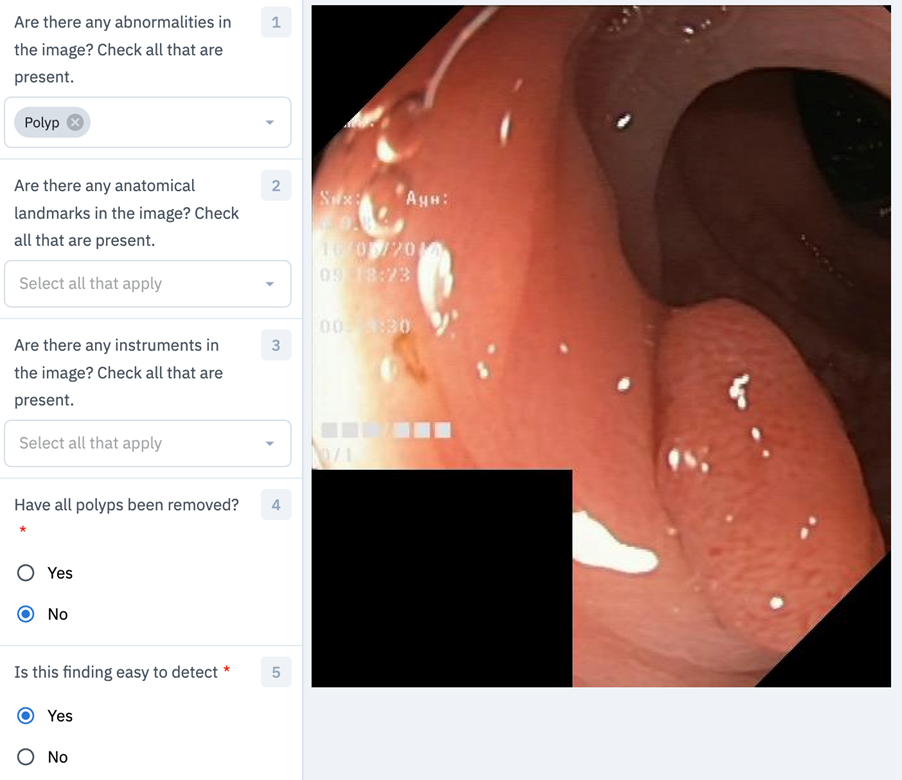
- In the visual question generation (VQG) subtask, the participants are asked to generate text questions from a given image and answer. Example questions for both VQA and VQG: How many polyps are in the image? Are there any polyps in the image? What disease is visible in the image?
- The third subtask is the visual location question answering (VLQA), where the participants get an image and a question and are required to answer it by providing a segmentation mask for the image. Example questions are: Where in the image is the polyp? Where in the image is the normal and the diseased part? What part of the image shows normal mucosa?
News
The development dataset is now released and can be accessed via: https://github.com/simula/ImageCLEFmed-MEDVQA-GI-2023
Task Description
Visual question answering (VQA)
The VQA task asks participants to generate text answers given a text question and image pair. For example, we provide an image containing a colon polyp with the following question, "Where in the image is the polyp located?". Here, the answer should be a textual description of where in the image the polyp is located, like upper-left or in the center of the image.
Visual question generation (VQG)
The VQG task asks participants to generate text questions based on a given text answer and image pair. This task is an inverse of task 1, where instead of generating the answer, we are asking for the question. An example could be given the answer "The image contains a polyp" and an image containing a polyp; the question should be "Does the image contain an abnormality?".
Visual location question answering (VLQA)
The VLQA task asks participants to segment parts of an image given a text question and image pair. This task differs from task 1 and task 2 as it requires a visual output rather than a textual one. For example, given the question "Where is the abnormality?" and an image containing a polyp, the output should give a segmentation mask covering the polyp in the image.
Data
The provided data will be based on the Hyper Kvasir dataset (datasets.simula.no/hyper-kvasir) with the additional question-and-answer ground truth, which will be developed with our medical partners. The data will include images spanning the entire gastrointestinal tract, from mouth to anus, and will include abnormalities, surgical instruments, and normal findings. This includes data from different procedures such as gastroscopy, colonoscopy and capsule endoscopy.
For task 1 (VQA) and task 2 (VQG), we will provide at least 5,000 image samples, each with five question-and-answer pairs. Not all questions will be relevant to the provided image, and we expect the submissions to be able to handle cases where there is no correct answer.
For task 3 (VLQA), we will provide at least 1,000 images with question and segmentation mask pairs. This part of the data will be based on the segmentation part of HyperKvasir and Kvasir Instrument.
Evaluation methodology
For assessing performance the following metrics will be used: F1 score, Accuracy, Recall, MCC, mIOU and Dice coefficient.
Participant registration
Please refer to the general ImageCLEF registration instructions
Preliminary Schedule
-
1 February 2023: Release of the training and validation sets
1st April 2023: Release of the test sets
22 April 2023: Registration closes
14 May 2023: Run submission deadline
17 May 2023: Release of the processed results by the task organizers
5 June 2023: Submission of participant papers [CEUR-WS]
23 June 2023: Notification of acceptance
7 July 2023: Camera ready copy of participant papers and extended lab overviews [CEUR-WS]
18-21 September CLEF Conference
Submission Instructions
To submit your entries for the CLEF 2023 Medical Visual Question Answering (MedVQA) Challenge, please follow these steps:
- Create a single zip file that includes a separate folder for each task you participated in.
- Name the zip file using this format: '<team_name>_clef2023_medvqa.zip'.
- Label the folders within the zip file as 'task1', 'task2', etc., corresponding to the respective tasks.
- Make sure to follow the detailed instructions and requirements for each task's submission, as described below.
Submissions can be emailed to the challenge organizers; Steven Hicks (steven@simula.no) and Michael Riegler (michael@simula.no).
Task 1: Visual Question Answering (VQA)
For Task 1, your submission should include a JSON file with the following format:
- The JSON file should contain one entry per image in the test dataset.
- Each entry should provide answers to the 18 questions listed in the table below.
- Entries should be formatted as key-value pairs, with the key being the image ID and the value being a list of answers.
You can test the correctness of your submission by running the `check_task_1_submission.py` script on your JSON file. This script will verify the formatting and structure of your file, ensuring it meets the requirements for evaluation. You can also check the `sample-submission` directory for an example JSON file that meets the aforemention requirements.
| Question ID | Questions | Question ID | Questions |
|---|---|---|---|
| 0 | What type of procedure is the image taken from? | 9 | How many instruments are in the image? |
| 1 | Have all polyps been removed? | 10 | Where in the image is the abnormality? |
| 2 | Is this finding easy to detect? | 11 | Where in the image is the instrument? |
| 3 | Is there a green/black box artifact? | 12 | Are there any abnormalities in the image? |
| 4 | Is there text? | 13 | Are there any anatomical landmarks in the image? |
| 5 | What color is the abnormality? | 14 | Are there any instruments in the image? |
| 6 | What color is the anatomical landmark? | 15 | Where in the image is the anatomical landmark? |
| 7 | How many findings are present? | 16 | What is the size of the polyp? |
| 8 | How many polyps are in the image? | 17 | What type of polyp is present? |
Task 2: Visual Question Generation (VQG)
Submissions for Task 2 are now open, and participants have the flexibility to submit a variety of materials related to their work. Some suggestions for submission content include:
- A collection of image-answer pairs, along with the generated questions associated with them.
- The source code used to create the question generation system, including any algorithms, libraries, or tools employed.
- A comprehensive report detailing the functionality and methodology of your question generation system, including any novel techniques or approaches used.
Please note that all submissions for Task 2 will be assessed through manual evaluation by a team of experts. This process will ensure a thorough and fair assessment of the quality, creativity, and effectiveness of each participant's question generation system.
Task 3: Visual Location Question Answering (VLQA)
Submissions for Task 3 follow a similar structure to Task 1, with a primary focus on answering questions related to segmentation. To participate in Task 3, please ensure your submission includes the following components:
- A JSON file formatted as described in Task 1, containing answers to the segmentation-related questions listed in the table below. This file should be organized with one entry per image in the test dataset and include key-value pairs, where the key represents the image ID and the value contains a list of corresponding answers.
- A separate directory containing the predicted segmentation masks associated with the answers provided in the JSON file. These masks should be organized and labeled in a manner that allows for easy correlation with the respective image IDs and corresponding questions.
By focusing on segmentation-related questions and providing both the JSON file and the predicted masks, participants will contribute valuable data to the evaluation of Task 3. This information will enable a comprehensive assessment of each submission's effectiveness in addressing the specific challenges associated with image segmentation in the medical domain. You can use the `verify_task_3_submission.py` script to check that your submission meets the requirements.
| Question ID | Questions | Question ID | Questions |
|---|---|---|---|
| 18 | Where exactly in the image is the polyp located? | 19 | Where exactly in the image is the instrument located? |
Results
Will be announced at the workshop.
CEUR Working Notes
More information to be added soon.
Citations
@inproceedings{ImageCLEF2023,
author = {Bogdan Ionescu, Henning M\"uller, Ana{-}Maria Dr\u{a}gulinescu, Wen{-}wai Yim, Asma {Ben Abacha}, Neal Snider, Griffin Adams, Meliha Yetisgen,
Johannes R\"uckert, Alba {Garc\’{\i}a Seco de Herrera}, Christoph M. Friedrich, Louise Bloch, Raphael Br\"ungel, Ahmad Idrissi{-}Yaghir, Henning Sch\"afer,
Steven A. Hicks, Michael A. Riegler, Vajira Thambawita, Andrea Storås, Pål Halvorsen, Nikolaos Papachrysos, Johanna Schöler, Debesh Jha,
Alexandra{-}Georgiana Andrei, Ahmedkhan Radzhabov, Ioan Coman, Vassili Kovalev, Alexandru Stan,
George Ioannidis, Hugo Manguinhas, Liviu{-}Daniel \c{S}tefan, Mihai Gabriel Constantin,
Mihai Dogariu, J\'er\^ome Deshayes, Adrian Popescu}
title = {{Overview of ImageCLEF 2023}: Multimedia Retrieval in Medical, SocialMedia and Recommender Systems Applications},
booktitle = {Experimental IR Meets Multilinguality, Multimodality, and Interaction},
series = {Proceedings of the 14th International Conference of the CLEF Association (CLEF 2023)},
year = {2023},
publisher = {Springer Lecture Notes in Computer Science LNCS},
pages = {},
month = {September 18-21},
address = {Thessaloniki, Greece}
}
To cite the working note paper:
@inproceedings{ImageCLEFmedicalCaptionOverview2023,
author = {Steven A. Hicks, Andrea Storås, Pål Halvorsen, Thomas de Lange, Michael A. Riegler, Vajira Thambawita},
title = {Overview of ImageCLEFmedical 2023 – Medical Visual Question Answering for Gastrointestinal Tract},
booktitle = {CLEF2023 Working Notes},
series = {{CEUR} Workshop Proceedings},
year = {2023},
volume = {},
publisher = {CEUR-WS.org},
pages = {},
month = {September 18-21},
address = {Thessaloniki, Greece}
}
Contact
Organizers:
- Steven A. Hicks <steven(at)simula.no>, SimulaMet, Norway
- Michael A. Riegler <michael(at)simula.no>, SimulaMet, Norway
- Vajira Thambawita <vajira(at)simula.no>, SimulaMet, Norway
- Andrea Storås <andrea(at)simula.no>, SimulaMet, Norway
- Pål Halvorsen <paalh(at)simula.no>, SimulaMet, Norway
- Thomas de Lange <thomas.de.lange(at)gu.se>, Sahlgrenska University Hospital, Sweden
- Nikolaos Papachrysos <nikolaos.papachrysos(at)vgregion.se>, Sahlgrenska University Hospital, Sweden
- Johanna Schöler <johanna.scholer(at)vgregion.se>, Sahlgrenska University Hospital, Sweden
- Debesh Jha <debesh.jha(at)northwestern.edu>, Norway & Northwestern University, USA